TiDB 스토리지
스토리지와 키-밸류의 기본 지식
소개
데이터베이스, 운영 체제, 컴파일러는 컴퓨터 소프트웨어를 구축하는 주요 기본 기반이다. 데이터베이스는 애플리케이션 계층에 가깝고 비즈니스를 지원하는 시스템으로 수십 년 동안 개발이 계속되고 있으며, 매일 진화하고 있다.
많은 사람들이 다양한 종류의 데이터베이스를 이용해 왔다고 생각하지만, 데이터베이스(특히 분산 데이터베이스)의 개발 경험이 있는 분은 극히 소수라고 생각한다. 데이터베이스 구현에서 알면 스킬 향상으로 이어질 뿐만 아니라 다른 시스템 구축에도 도움이 되며 데이터베이스를 능숙하게 활용할 수 있다.
기술 이해를 깊게 하는 가장 좋은 방법은 그 분야의 오픈 소스 프로젝트에 몰두하는 것이라고 필자는 생각한다. 데이터베이스 분야에도 많은 훌륭한 오픈 소스 프로젝트가 있다. 이 프로젝트를 통해, 특히 유명한 MySQL과 PostgreSQL 소스 코드를 본적이 있는 사람도 많을 것이다. 분산 데이터베이스 분야에서 TiDB도 인정받는 몇 안되는 프로젝트로 위 제품과 마찬가지로 소스 코드를 읽을 수도 있다.
그러나, 분산 데이터베이스는 복잡하기 때문에 많은 기술자에게 전체 프로젝트를 이해하는 것이 어려운 것 같다. 그 때문에, 필자는 TiDB의 기술을 알기 쉽게 해설하는 기사를 정리하기로 했다. 오픈 소스로부터 읽을 수 있는 테크닉 뿐만이 아니라, SQL 인터페이스의 배후에 숨겨져 있는 구현시의 테크닉등도 다수 소개 하겠다.
데이터 저장
데이터베이스의 가장 기본적인 기능인 데이터 저장에 대해 설명한다. 데이터를 저장하는 방법에는 여러 가지가 있다. 가장 간단한 방법은 메모리에 데이터 구조를 구축하고 사용자가 보낸 데이터를 저장하는 방법이다. 예를 들어, 배열을 사용하여 데이터를 저장하고 데이터를 받으면 배열에 새 항목을 추가할 수 있다. 이 솔루션은 간단하고 기본적인 요구를 충족하며 성능이 뛰어나다. 그러나 이러한 장점을 능가하는 단점이 있다. 가장 큰 문제는 모든 데이터가 메모리에 저장되므로 서버가 중지되거나 다시 시작될 때 데이터가 손실된다는 것이다.
데이터 지속성을 달성하는 수단으로는 디스크와 같은 비휘발성 스토리지에 데이터를 저장하는 것이다. 디스크에 파일을 만들고 데이터를 받으면 파일에 새 데이터를 추가한다. 이는 지속 가능한 스토리지 솔루션이지만 이것만으로는 충분하지는 않다. 왜냐하면 저장된 디스크가 손상되면 데이터가 손실되기 때문이다. 따라서 디스크가 손상된 경우를 가정하고 RAID(Redundant Array of Independent Disks)에서 중복하여 사용한다. 하지만 기계가 다운되면 어떻게 될까? 데이터에 더 이상 액세스할 수 없다.
RAID는 안전한 저장 장소가 아니다. 그 외에도 네트워크를 통해 스토리지에 데이터를 저장하는 방법과 중복 소프트웨어를 이용하여 하드웨어 수준에서 복제하는 방법 등이 있다. 이러한 방법의 문제는 복제할 때 일관성을 유지하는 것이다. 데이터 무결성(무손상성)과 정확성 보호는 기본 요구 사항이며, 이를 달성하기 위해 아래에 같은 어려운 문제가 있다.
- 빠른 쓰기 속도가 필요하다.
- 저장 시 데이터를 일관성 있게 읽어야 한다.
- 동시 수정을 처리해야 한다.
- 여러 레코드를 원자적으로 수정해야 한다.
이러한 문제는 모두 해결하기 어렵지만, 모든 것을 해결할 수 있어야 뛰어난 데이터베이스 스토리지 시스템이라고 할 수 있다.
이러한 배경을 바탕으로 당사는 TiDB의 데이터스토어 부분인 TiKV를 개발하였다. 우선, SQL의 개념은 잊고, 고성능으로 고신뢰의 분산 키 밸류 스토어의 TiKV의 구현 방법을 소개하겠다.
※ TiKV는 KVS로 이용하실 수 있다.
키-밸류(key-value)
데이터 스토리지 시스템의 첫 번째 가장 중요한 단계는 데이터 저장 모델을 결정하는 것이다. 즉, 어떤 형식으로 데이터를 저장해야 하는지를 결정하는 것이다. TiKV는 원래 바이트 배열이 키와 값으로 구성된 거대한 맵으로 생각할 수 있다. 이 맵에서는 키가 바이트 배열의 원시 바이너리 비트에 따라 비교 순서로 배치된다. 다음 사항에 유의해야 한다.
- 이는 키-밸류 쌍으로 구성된 거대한 지도이다.
- 이 맵에서 키-밸류 쌍은 키의 이진 시퀀스에 따라 순서가 지정된다. 사용자는 키의 위치를 탐색하고 다른 키 값 쌍에 대해 다음 메소드를 사용할 수 있다. 이 키-밸류 쌍은 모두 이것보다 커진다.
여기에서 언급한 스토리지 모델과 SQL 테이블 간의 관계는 무엇인가? 라고 의문을 느끼고 있는 사람도 있을 것이다. 분명히 말한다. 무관한다.
RocksDB, Raft 및 Region의 개념
앞에서 데이터의 격납 및 키 밸류를 설명하였다. 이번 RocksDB, Raft와 리전을 소개하겠다.
RocksDB
지속 가능한 스토리지 엔진은 데이터를 디스크에 저장한다. TiKV도 예외는 아니다. 그러나 TiKV는 디스크에 직접 데이터를 쓰지 않는다. 먼저 TiKV가 RocksDB에 데이터를 저장하고 RocksDB가 데이터 저장을 수행한다. 독립 실행형(Stand-alone) 스토리지 엔진(특히 고성능 독립 실행형 엔진)의 개발은 상당한 비용이 들기 때문이다. 다양한 최적화 처리에 다가서는 것이다.
PingCAP회사는 RocksDB가 모든 요구 사항을 충족하는 탁월한 오픈 소스 독립형 스토리지 엔진임을 발견하였다. Facebook팀이 이 엔진의 최적화에 매진하고 있는 동안, PingCAP사는 그렇게 어려움이 없이 개량이 진행되는 강력한 독립형 엔진을 즐길 수 있다는 장점도 있다. 물론, PingCAP사도 RocksDB에 대해서 약간의 코드 제공하고는 있지만, 이 프로젝트의 추가 개선이 기대하기는 힘들다. 간단히 말해 RocksDB는 독립형 키-밸류 맵으로 볼 수 있다.
Raft
이 복합 프로젝트의 첫번째로 중요한 단계는, 안정적이고 효과적인 로컬 스토리지 솔루션을 찾는 것이었다. 다음은 1대의 컴퓨터가 정지할 때 데이터의 무결성과 정확성을 어떻게 보호하는가에 대한 비교적 어려운 과제이다. 효과적인 것은 데이터를 여러 대의 컴퓨터에 복제하는 방법이다.
그렇게 되면 1대의 컴퓨터가 충돌할 경우, 다른 컴퓨터의 복제본을 사용할 수 있다. 그러나, 복제 솔루션은 유효하지 않은 복제본이 있는 상황에 대응할 수 있는 안정적이고 효과적이어야 한다. 어려울 것 같지만 Raft를 이용하면 실현할 수 있다. Raft는 Paxos보다 이해하기 쉬운 Paxos와 동등한 합의 알고리즘이다. Raft에 관심이 있으시면 Raft의 논문을 읽으시면 자세한 내용을 볼 수 있다. 이 외부 Raft 보고서는 기본적인 솔루션만을 제시하고 있으며, 이 보고서를 엄격하게 준수하면 성능이 낮아진다는 것을 지적한다. PingCAP는 Raft를 구현하기 위해 다양한 최적화를 수행하였다.
Raft는 합의 알고리즘이며, 다음과 같은 세 가지 중요한 기능이 있다.
- 리더 선출
- 멤버십 변경
- 로그 복제
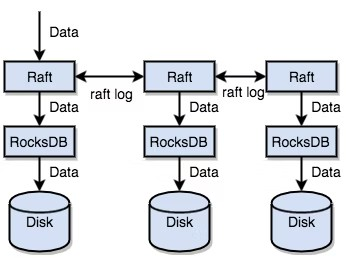
TiKV는 Raft를 사용하여 데이터를 복제한다. 각 데이터 변경은 Raft 로그로 기록된다. 데이터는 Raft의 로그 복제 기능을 통해 Raft 그룹의 여러 노드와 안전하고 안정적으로 동기화된다.
요약하면 독립 실행형 RocksDB를 사용하면 데이터를 디스크에 빠르게 저장할 수 있다. Raft를 사용하면 시스템 장애에 대비하여 여러 시스템에 데이터를 복제할 수 있다. 데이터는 RocksDB에 대한 것이 아니라 Raft 인터페이스를 통해 기록된다. Raft 구현 덕분에 분산형 키-밸류 시스템을 이용할 수 있게 되어, 이제는 컴퓨터의 장애에 대해 걱정할 필요가 없다.
Region
이 섹션에서는 매우 중요한 개념 “리전(지역, region)“에 대해 소개한다. 리전은 일련의 메커니즘을 이해하는데 있어서 기초가 된다. 이 개념을 고려하기 전에 Raft를 잊어 버리고 모든 데이터에 복제본이 하나만 있다는 상황을 상상해보자.
앞서 언급했듯이 TiKV는 순서가 지정된 거대한 키-밸류 맵으로 볼 수 있다. 스토리지의 수평 확장성을 얻으려면 여러 시스템에 데이터를 분산시켜야 한다.
키-밸류 시스템에는 여러 컴퓨터에 데이터를 분산시키는 두 가지 일반적인 솔루션이 있다. 하나는 해시를 만들고 해시 값을 기반으로 해당 스토리지 노드를 선택하는 솔루션이다. 다른 하나는 범위를 사용하고 직렬 키 세그먼트를 스토리지 노드에 저장하는 솔루션이다. TiKV는 두 번째 솔루션을 선택하고 전체 키 가치 공간을 여러 세그먼트로 나눈다. 각 세그먼트는 인접한 키 세트로 구성된다. 이러한 세그먼트를 당사는 ‘리전’이라고 부른다. 각 리전이 저장할 수 있는 데이터의 크기에는 상한이 있다(기본값은 64MB, 이 사이즈는 설정 가능). 각 리전은, 왼쪽이 열리고 오른쪽이 닫힌 구간(StartKey로부터 EndKey까지)에 의해 표현할 수 있다.
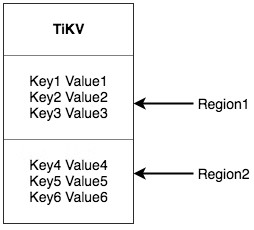
지금 여기서 말하고 있는 리전은 SQL의 테이블과는 아무 관계도 없다! 지금은 SQL을 잠시 잊고 키-밸류에 집중하자.
데이터를 리전으로 분할한 후 다음과 같은 두 가지 중요한 작업을 수행한다.
- 클러스터의 모든 노드에 데이터를 분산하고 지역을 데이터 이동의 기본 단위로 사용한다. 각 노드의 리전 수가 거의 같은지 확인해야 한다.
- 지역에서 Raft를 통한 복제 및 멤버십 관리.
이 두 가지 작업은 매우 중요하기 때문에 하나씩 설명한다.
첫 번째 태스크에서는 키를 기반으로 데이터를 여러 리전으로 나누고, 각 리전의 모든 데이터를 하나의 노드에 저장한다. 모든 클러스터 노드에 대한 지역의 균등 분산은 당사 시스템의 한 구성 요소가 담당한다. 그 결과, 스토리지 용량의 수평 확장성이 제공된다(새 노드가 추가될 때 시스템이 자동으로 다른 노드에서 리전을 스케줄대로 처리한다). 반면에 부하 분산도 달성된다(즉, 한 노드에 많은 데이터가 배치되고, 다른 노드에는 적게 배치되는 상황이 발생하지 않음). 동시에 상위 클라이언트가 필요한 데이터에 액세스할 수 있도록 하기 위해 다른 구성 요소(component)가 여러 노드에 걸쳐서 리전의 분산을 기록한다. 즉, 사용자는 키의 정확한 리전과 키를 통해 배치된 해당 리전의 노드를 조회할 수 있다. 이 두 가지 구성 요소는 나중에 자세히 설명한다.
두 번째 작업으로 이동하자. TiKV는 리전의 데이터를 복제한다. 즉, 하나의 리전의 데이터에는 “Replica"라는 이름의 여러 복제본이 있다. 복제본 간의 데이터 일관성을 달성하려면 Raft가 사용된다. 한 리전의 여러 복제본이 여러 개의 다른 노드에 저장되고 Raft 그룹을 구성한다. 한 복제본이 그룹의 리더 역할을 하고 다른 복제본이 팔로어가 된다. 읽기와 쓰기는 모두 리더를 통해 이루어지며 리더가 팔로어에 복제한다.
다음 그림은 리전과 Raft 그룹의 전체 이미지를 표시해주고 있다.
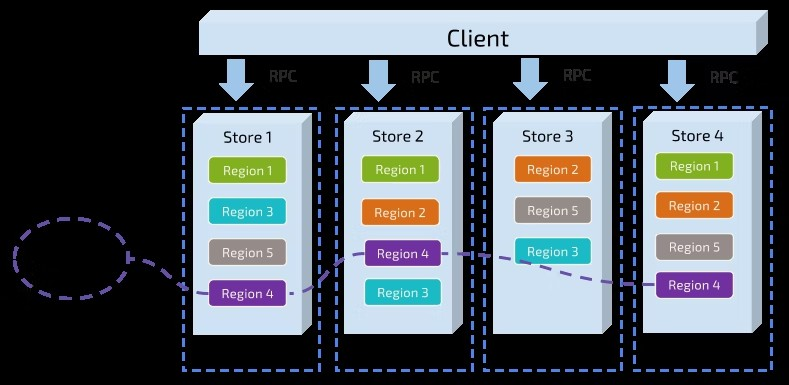
리전에서 데이터를 분산 및 복제할 때는 어느 정도 재해 복구 능력을 가진 분산형 키 밸류 시스템을 활용할 수 있다. 이제 사용자는 용량이나 디스크 장애로 인한 데이터 손실 문제로 고민할 필요가 없다. 이것은 훌륭하지만 완벽하지는 않다. 필요한 기능이 있다.
MVCC와 트랜잭션
앞에서 데이터의 저장, 키 밸류, RocksDB, Raft와 리전등 개념을 소개하였다. 여기에서는 MVCC와 트랜잭션을 소개하겠다.
MVCC
많은 데이터베이스는 여러 버전의 동시 제어(MVCC: Multi-Version Concurrency Control)를 수행한다. TiKV도 예외는 아니다. MVCC를 통하지 않고 두 클라이언트가 키 값을 동시에 업데이트하면 데이터가 락(Lock)이 걸린다. 분산 시나리오에서 이러한 처리는 성능 문제나 교착 상태 문제로 이어진다.
TiKV는 키에 버전을 추가하여 MVCC를 실현한다. MVCC를 수행하지 않으면 TiKV의 데이터 레이아웃은 다음과 같다.
Key1 -> Value
Key2 -> Value
...
KeyN -> Value
MVCC를 수행하면 TiKV의 키 배열은 다음과 같다.
Key1-Version3 -> Value
Key1-Version2 -> Value
Key1-Version1 -> Value
...
Key2-Version4 -> Value
Key2-Version3 -> Value
Key2-Version2 -> Value
Key2-Version1 -> Value
...
KeyN-Version2 -> Value
KeyN-Version1 -> Value
...
키에 여러 버전이 있다면, 가장 큰 숫자를 먼저 배치한다(필요한 경우 키와 정렬된 배열이라고 설명한 키 값 섹션을 다시 살펴보길 바란다). 이와 같이, 키에 버젼을 추기해 값을 받아올 때에는 키와 버젼을 사용한 MVCC의 키(Key-Version)를 구축할 수 있다. 그런 다음 Seek(Key-Version)을 직접 실행하여 이 Key-Version 이후의 첫 번째 위치를 찾을 수 있다.
트랜잭션
TiKV의 트랜잭션은 퍼콜레이터(percolator) 모델을 채택하고 있으며, 많은 최적화가 이루어지고 있다. 여기서 언급하고 싶은 것은 TiKV의 트랜잭션이 낙관적인 잠금을 사용한다는 것이다. TiKV의 트랜잭션은 실행 프로세스에서 쓰기 충돌을 감지하지 않는다. 충돌을 감지하는 것은 커밋 단계에서만 발생한다. 먼저 커밋을 종료하는 트랜잭션은 성공적으로 기록되지만, 다른 트랜잭션은 다시 시도한다. 그 회사의 쓰기 경쟁이 심각하지 않으면, 이 모델의 성능은 매우 좋다. 예를 들어 대형 테이블의 여러 데이터 행을 무작위로 업데이트하는 작업에 어려움없이 대응할 수 있다. 그러나, 쓰기 충돌이 심각하면 성능이 낮아 진다. 카운터는 극단적인 예라고 생각하길 바란다. 많은 클라이언트가 몇몇의 행을 동시에 업데이트하는 상황은 심각한 충돌과 다수의 잘못된 재시도로 이어진다.
마무리
스토리지 편의 기사에서는 TiKV의 기본 개념과 약간의 세부 사항, 이 분산형 트랜잭션 키 밸류 엔진의 레이어 구조, 멀티 데이터 센터의 재해 복구를 실현하는 방법 등을 소개하였다. 다음 기사에서는 분산 데이터베이스 TiDB의 컴퓨팅에 대해 소개한다.