데이터 중심 애플리케이션 설계 | 11장. 스트림 처리
발표자 : 김경철, 김민규
스트림 : 시간 흐름에 따라 점진적으로 생산된 데이터
스트림 처리 : 일괄 처리와 다르게, 단순히 이벤트가 발생할 때마다 처리한다.
이벤트 스트림 : 점진적인 처리, 시간별로 정렬된 일련의 비즈니스 이벤트
이벤트 스트림 전송
이벤트
- 특정 시점에 일어난 사건에 대한 세부 사항을 포함
- 일반적으로 일기준 시계를 따르는 이벤트 발생 타임스탬프 포함
이벤트 예제
- 웹페이지를 보거나 상품을 구입하는 일 같은 사용자가 취한 행동
- 온도 센서 주기적으로 측정한 값이나 CPU 사용률 지표와 같이 같이 장비에서 발생한 것
- 웹 서버 로그의 각줄을 이벤트 하나로 취급
이벤트의 부호화, 저장, 전송
- 텍스트 문자열이나 JSON 또는 이진 형태 등으로 부호화 가능
- 파일 및 관계형 테이블에 삽입 및 문서 데이터베이스로 기록하거나 저장 가능
- 다른 노드에서 처리하게끔 네트워트를 통해 전송 가능
생산자와 소비자
- 생산자(producer), 발생자(pubisher), 발송자(sender)는 이벤트를 만든다.
- 소비자(consumer), 구독자(subscriber), 수신자(recipient)는 이벤트를 처리한다.
- 스트림 시스템에서는 토픽(topic)이나 스트림으로 관련 이벤트를 묶는다.
스트림 처리와 일괄 처리 비교
- 스트림 처리
- 생산자는 만들어낸 모든 이벤트를 데이터스토어 기록한다.
- 각 소비자는 주기적으로 데이터스토어에 폴링해 마지막에 처리한 이후에 새로 발생한 이벤트가 있는지 확인하고 처리한다.
- 일괄 처리
- 매일 마지막에 그날 데이터 분량을 처리한다.
- 차이점
- 스트림 처리 발생할 때마다 확인하고 처리한다.
- 일괄 처리 모와서 처리한다.
- 공통점
- 마지막 처리된 이후로 이어서 처리한다.
메시징 시스템
메시징 시스템(messaging system) 역할
- 새로운 이벤트에 대해 소비자에게 알려주려고 쓰이는 일방적인 방법으로 메시징 시스템을 사용한다.
- 생산자는 이벤트를 포함한 메시지 전송한다.
- 소비자는 그 메시지를 전달 받는다.
생산자와 소비자 연결
- 유닉스 파이프, TCP 연결
- 생산자와 소비자 사이를 직접 통신 채널을 사용하는 방법
- 메시지 시스템을 구축하는 가장 간단한 방법
- 전송자 하나를 정확히 수신자 하나에 연결
- 생산자와 소비자 사이를 직접 통신 채널을 사용하는 방법
- 메시징 시스템
- 다수의 생산자 노드가 같은 토픽(topic)으로 메시지를 전송한다.
- 다수의 소비자 노드가 토픽(topic) 하나에서 메시지를 받아 간다.
발생/구독(publish/subscribe, pub/sub) 모델에서의 시스템들의 다양한 접근법
- 생산자가 소비자가 메시지를 처리하는 속도보다 빠르게 메시지를 전송한다면 어떻게 될까?
- 3가지 선택지
- 시스템 메시지를 버린다.
- 큐에 메시지를 버퍼링한다.
- 배압(backpressure)을 적용한다.
- 흐름 제어(flow control)이라고 한다.
- 생산자가 메시지를 더 보내지 못하게 막는다.
- 유닉스 파이프와 TCP을 배압을 사용한다.
- 메시지가 큐에 버퍼링될 때, 큐 크기가 증가하게 된다면?
- 큐 크기가 메모리 크리보다 더 커지면 시스템이 중단되는가?
- 메시지를 디스크에 쓰는가?
- 쓴다면 메시징 시스템의 성능에 어떤 영향을 주는가?
- 3가지 선택지
- 노드가 죽거나 일시적으로 오프라인이 된다면 어떻게 될까? 손실되는 메시지가 있을까?
- 지속성을 갖추려면? 비용 발생
- 디스크에 기록
- 복제본 생성
- 둘 다 필요
- 메시지를 읽어도 된다면? 비용 절약
- 하드웨어 처리량을 높일 수 있다.
- 지연 시간을 낮출 수 있다.
- 지속성을 갖추려면? 비용 발생
메시지의 유실
- 메시지가 유실된다면, 애플리케이션에 따라 다르다.
- 주기적으로 전송되는 데이터(센서 판단값, 지표)
- 가끔 누락되면 문제가 없다.
- 단, 많이 누락되면 정확성이 떨어지고 인식하기 어렵다.
- 이벤트 수가 데이터인 경우
- 누락으로 인해 카운터가 잘못되었다는 것을 의미하기에 신뢰성이 떨어진다.
- 주기적으로 전송되는 데이터(센서 판단값, 지표)
생산자에서 소비자로 메시지를 직접 전달하기
중간 노드를 통하지 않고, 생산자와 소비자를 네트워크로 직접 통신
- UDP 멀티캐스트
- 낮은 지연이 필수인 주식 시장과 같은 금융 산업에서 널리 사용된다.
- UDP 자체는 신뢰성이 낮아도 애플리케이션 단의 프로토콜은 읽어버린 패킷을 복구 할 수 있다.
- 생성자는 필요할 때 패킷을 재전송할 수 있게 전송한 패킷을 기억해야 한다.
- ZeroMQ, 나노메시지(nanomsg)
- 유사한 접근법 사용한다.
- TCP 또는 IP 멀티캐스트 상에서 발행/구독 메시징을 구현한다.
- ZeroMQ
- 분산/동시성 애플리케이션에 사용하도록 개발된 고성능 비동기 메시지 라이브러리이다.
- 메시지 큐를 제공하지만 메시지 지향 미들웨어와 달리 메시지 브로커 없이 동작 가능하다.
- 나노메시지(nanomsg)
- 일반적인 통신 패턴을 제공하는 소켓 라이브러리이다.
- 네트워크 계층에 빠르고 확장 가능하며 사용하기 쉽게 만드는 것을 목표로 한다.
- 유사한 접근법 사용한다.
- StatsD, BruBeck
- 네트워크 상의 모든 장비로부터 지표를 수집하고 모니터링하는데 UDP 메시징을 사용한다.
- 소비자가 네트워크 서비스를 노출하면 생산자는 직접 HTTP나 RPC 요청
직접 메시징 시스템의 한계
- 메시지가 유실 될 수 있는 가능성을 고려하여 애플리케이션 코드를 작성해야 한다.
- 소비자가 오프라인이라면 메시지를 전달하지 못하는 상태에서 있는 동안 전송된 메시지는 잃어 버릴 수 있다.
메시지 브로커
메시지 브로커(메시지 큐)
- 직접 메시징 시스템의 대안으로 메시지 브로커를 통해 메시지를 보내는 방법이 있다.
- 메시지 스트림을 처리하는데 최적화된 데이터베이스의 일종이다.
- 메시지 브로커는 서버로 구동되고, 생성자와 서비자는 서버의 클라이언트로 접속한다.
- 생성자는 브로커로 메세지 전송한다.
- 소비자는 브로커에서 메세지를 읽어 전송받는다.
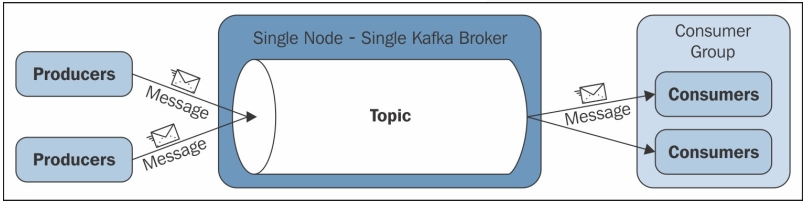
메세지 브로커의 이점
- 클라이언트의 상태 변경(접속, 접속 해제, 장애)에 쉽게 대처할 수 있다.
- 브로커가 장애로 중단됐을 때도 메시지를 디스크에 기록하게 되면 유실되지 않는다.
- 메모리에만 메시지를 보관하는 브로커는 유실될 수 있다.
- 소비 속도가 느리면 브러커는 큐에 제한 없이 계속 늘어나게 한다.
- 메시지를 버리거나 배압을 하지 않는다. 다만, 이는 설정으로 변경할 수도 있다.
큐에 대기하게 되면 소비자는 비동기로 동작
- 생산자는 메시지를 브로커에 보내면 해당 메시지는 버퍼에 쌓이게 되고, 소비가 될 때까지 기다리지 않는다.
- 소비자는 메시지를 바로 소비할도 있지만, 늦게 소비할 수도 있게 된다.
메시지 브로커와 데이터베이스 비교
- 데이터 보관
- 데이터베이스 : 데이터가 삭제될 때까지 보관
- 메시지 브로커 : 소비자에게 데이터가 전달되면 자동으로 삭제
- 데이터 크기
- 메시지 브로커: 대부분의 메시지 빨리 지우기 때문에 작업 집합이 상당히 작다고 가정한다.
- 소비자가 많은 메시지를 버퍼링해야 한다면 처리량이 저하된다.
- 작업 집합이란? 현재 실제 메모리에 상주하는 프로세스의 가상 주소 공간을 있는 페이지 집합이다.
- 메시지 브로커: 대부분의 메시지 빨리 지우기 때문에 작업 집합이 상당히 작다고 가정한다.
- 데이터 검색
- 데이터베이스 : 색인 등 다양한 검색 방법을 지원
- 메시지 브로커 : 특정 패턴과 부합하는 토픽의 부분 집합을 구독하는 방식 지원
- 메커니즘을 다르지만 둘 다 본질적으로 클라이언트가 데이터에서 필요한 부분만 선택하는 방법이다.
- 데이터 질의
- 데이터베이스 : 질의할 때 그 결과는 질의 시점의 데이터 스냅숏을 기준으로 한다.
- 데이터 변경되면 다시 질의하거나 풀링하지 않으면 변경되었다는 것을 알 수가 없다.
- 메시지 브로커 : 임의 질의를 지원하지 않지만, 변경되면 클라이언트에게 알려 준다.
- 데이터베이스 : 질의할 때 그 결과는 질의 시점의 데이터 스냅숏을 기준으로 한다.
이것은 메시지 브로커의 전통적인 관점으로 JMS, AMQP 같은 표준으로 캡슐화 되어 다음과 같은 소프트웨어로 구현되었다.
- RabitMQ, ActivceMQ, 큐피드(Qpid), 호빗Q(HornetQ), TIBCO Enterprice Message Service, IBM MQ, Azure Service Bus, 구글 클라우드 Pub/Sub
JMS(Java Message Service)
- Java EE에서 기반한 애플리케이션 구성요서에서 메시지를 작성, 전송, 수신하고 읽을 수 있도록 하는 API이다.
- 서버 구성을 통해 큐, 주제, 연결, 기타 자원을 작성 및 관리하는 관리 모드로 실행할 수 있다.
AMQP(Advanced Message Queuing Protocal)
- 메시지지향 미들웨어를 위한 개방형 표준 응용 계층 프로토콜이다.
- 메시지지향, 큐잉, 라우팅(P2P 및 발행-구독), 신뢰성, 보안 기능이 있다.
복수 소비자
여러 소비자가 같은 토픽에서 메시지를 읽을 때 사용하는 주요 패턴 2가지
- 로드 밸런싱
- 각 메시지는 소비자 중 하나로 전달된다.
- 브로커는 메시지를 전달할 소비자를 임의로 지정한다.
- 팬 아웃(fan-out)
- 각 메시지는 모든 소비자에게 전달된다.
- 여러 독립적인 소비자가 브로드캐스팅된 동일한 메시지를 서로 간섭 없이 전달 받을 수 있다.
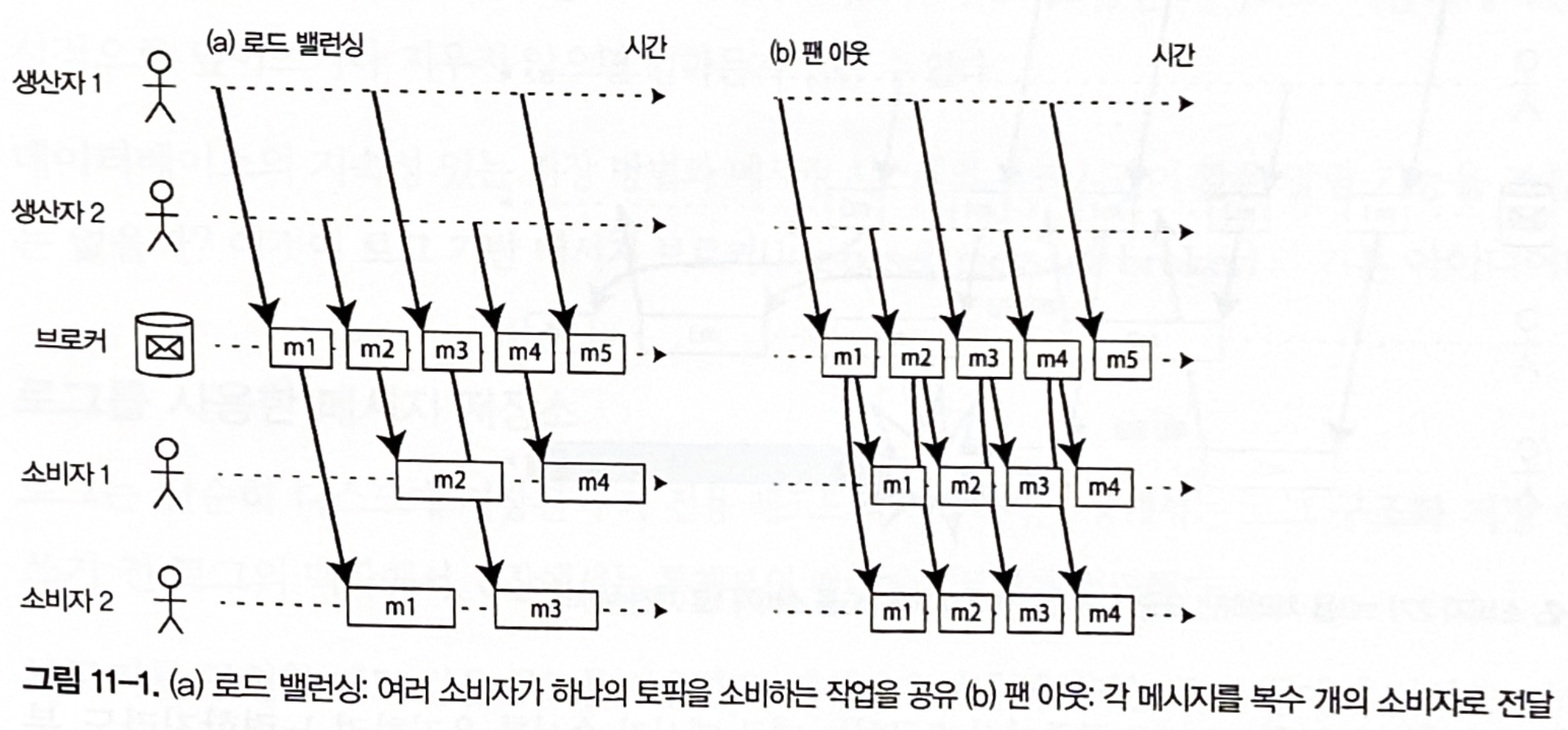
그림 11-1. (a) 로드 밸런싱: 여러 소비자가 하나의 토픽을 소비하는 작업을 공유 (b) 팬 아웃: 각 메시지를 복수 개의 소비자로 전달
Fan In, Fan Out
팬 아웃(영어: fan out)은 논리 회로에서 하나의 논리 게이트의 출력이 얼마나 많은 논리 게이트의 입력으로 사용되는지에 대해 서술할 때에 쓰인다. (출처: 위키 백과)
Fan In : 자신을 사용하는 모듈의 수 (A:0, B:1, C:1, D:1, E: 1, F:2, G:1, H:2, I:1, J:1)
Fan Out: 자신이 호출하는 모듈의 수(A:3, B:2, C:2, D:1, E:1, F:1, G:1, H:0, I:0, J:0)
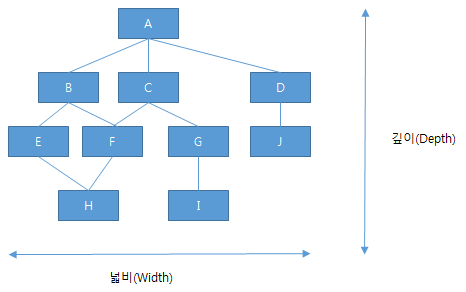
프로그램의 계층적 구조
출처: https://ehclub.co.kr/1851 [언제나 휴일]
이 두가지 패턴을 함께 사용 가능
- 두 개의 소비자 그룹에서 하나의 토픽을 구독한다.
- 각 그룹은 모든 메시지를 받지만, 그룹 내에서는 각 메시지를 하나의 노드만 받게 하는 식이다.
확인 응답과 재전송
소비자 장애
- 브로커가 메시지를 소비자에게 전달을 했지만, 처리하지 못하거나 부분적으로만 처리 후에 장애가 발생할 수 있다.
- 이럴 때는 메시지가 유실 될 수 있기 때문에 브로커는 확인 응답을 사용한다.
- 클라이언트는 메시지 처리가 끝났을 때, 브로커에게 명시적으로 알려주고 브로커는 해당 메시지를 제거한다.
확인 응답이 안되면
- 확인 응답을 받지 전에 클라이언트가 연결이 되지 않거나, 타임아웃이 발생하면 브로커는 처리가 되지 않았다고 간주하고 다른 소비자에게 다시 전송한다.
- 메시지 처리가 되었는데도 불가하고 확인 응답 되지 않았다면, 원자적 커밋 프로세스가 필요하다.
원자적 커밋(atomic commit)이란?
원자적 커밋(atomic commit)은 구별되는 여러 변경사항들을 하나의 운용 단위로 적용하는 것이다. 변경사항이 적용되면 원자적 커밋은 성공하였다고 이야기된다. 원자적 커밋이 끝나기 전에 실패한 것이 하나라도 있다면 원자적 커밋에서 완수되는 모든 변경사항들이 되돌려진다.부하 균형 분산과 결합할 때 이런 재전송 행위는 메시지 순서에 영향을 미친다.
- 소비자1이 m4를 처리하고 있을 때, 소비자2가 m3를 처리할 시에 장애 발생한다.
- m3의 확인 응답을 받지 못해 소비자1로 재전송하게 된다.
- 소비자1은 m4, m3, m5순으로 메시지를 처리하게 된다.
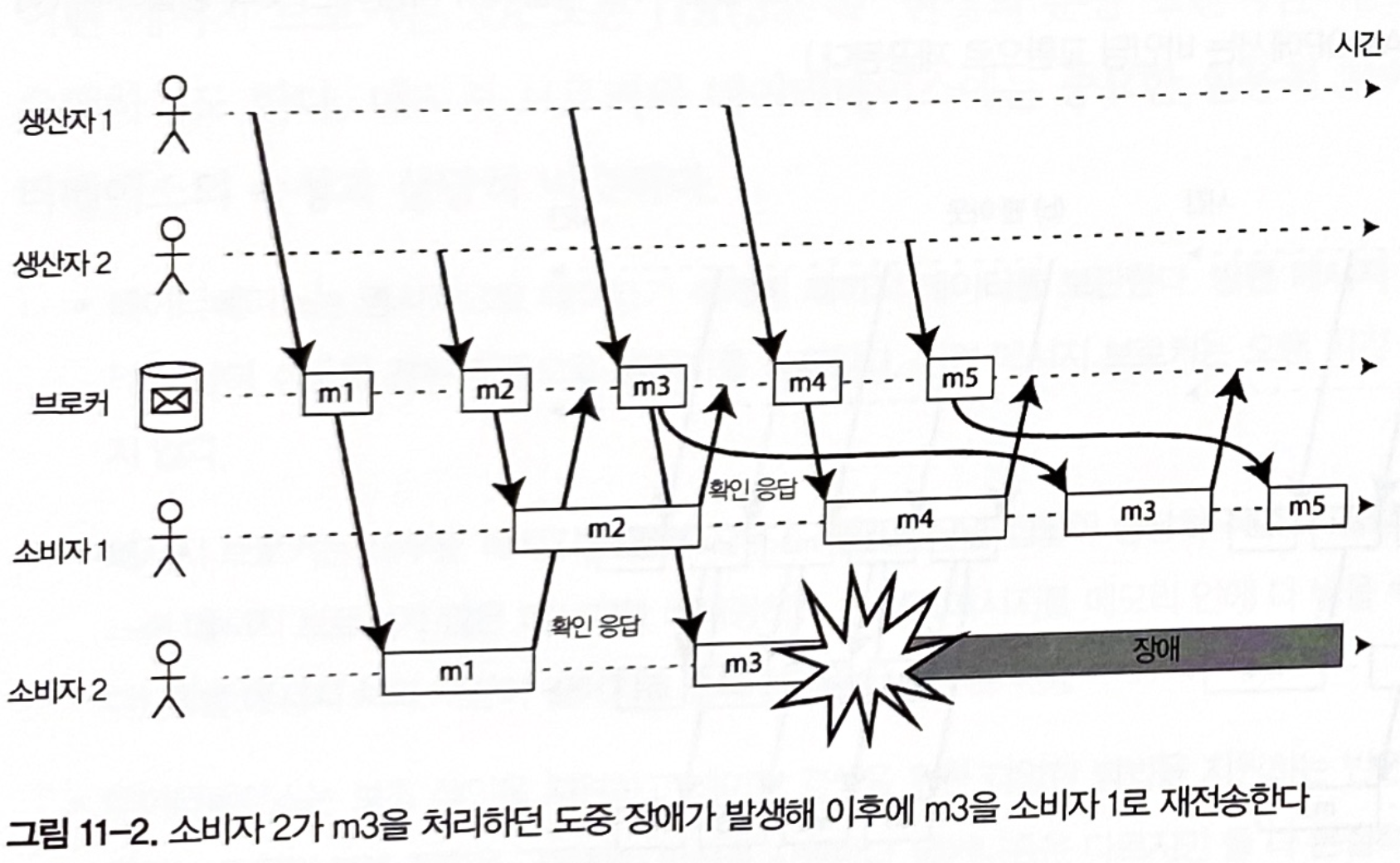
그림 11-2. 소비자 2가 m2을 처리하던 도중 장애가 발생해서 이후 m3을 소비자 1로 재전송한다
메시지 브로커는 순서를 유지하려고 노력하더라도 이렇게 변경될 수도 있다.
부하 균형 분산 기능을 사용하지 않는다면 이 문제를 피할할 수 잇다.
메시지 간에 인관성이 있다면 순서는 중요하다. (이 문제는 후반부에서 다룬다.)
파티션닝된 로그
기록을 남지지 않는 메시지 브로커
- 패킷을 전송하거나 서비스에 요청하는 작업은 보통 영구적 추적을 남기지 않는 일시적 연산이다.
- 메시지 브로커도 디스크에 지속성 있기 기록을 하지만, 소비자가 전달될 후 즉시 삭제한다.
- 메시지 브로커는 일시적 보관 개념으로 만들어 졌다.
- 메시지 브로커는 메시지가 전달을 하게 되면, 확인 응답을 받고 삭제한다. 이는 복구되지 않는다.
기록하는 데이터 베이스
- 데이터베이스나 파일에 저장하는 모든 데이터는 누군가 삭제하지 않으면 영구적으로 보관된다.
데이터베이스의 지속성 있는 저장 방법과 메시징 시스템 지연 시간이 짧은 알림 기능의 조합이 로그 기반 메시지 브로커(log-based message broker) 이다.
로그를 사용한 메시지 저장소
로그란?
- 단순히 디스크에 저장된 추가 전용 레코드의 연속이다.
- 로그 구조화 저장 엔진과 쓰기 전 로그, 복제본의 로그와 같은 맥락
브로커에서 로그는?
- 생산자가 보낸 메시지는 로그 끝에 추가한다.
- 소비자는 로그를 순차적으로 읽어 메시지를 받는다. 로그 끝에 도달하면 새 메시지가 추가됐다는 알림을 기다린다.
로그 파티셔닝
- 디스크 하나를 쓸 때보다 로그 처리량을 높이기 위해 파티셔닝을 하는 방법이다.
- 다른 피티션은 다른 장비에서 서비스할 수 있다.
- 각 파티션은 다른 파티션과 독립적으로 읽고 쓰기가 가능한 로그가 된다.
오프셋(offset)
- 각 파티션 내에서 브로커는 모든 메시지에 단순히 증가하는 순번인 오프셋을 부여한다.
- 다른 파티션 간 메시지의 순서는 보장하지 않는다.
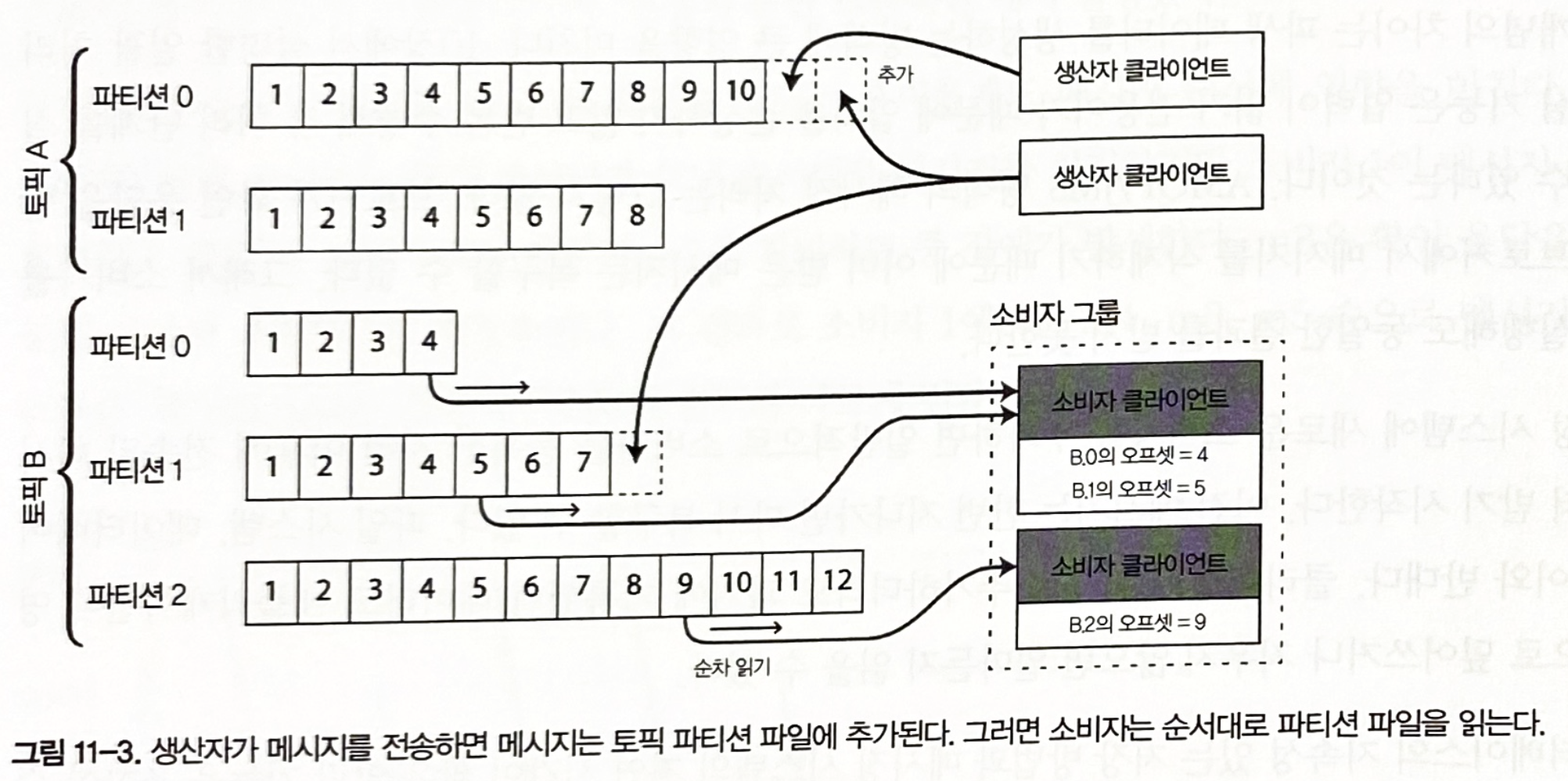
그림 11-3. 생산자가 메시지를 전송하면 메시지는 토픽 파티션 파일에 추가된다. 그러면 소비자는 순서대로 파티션 파일을 읽는다.
이 방식은
- 아파치 카프카, 아마존 키네스티 시스템, 트위터의 분산 로그가 이런 방식으로 동작하는 로그 기반 메시지 브로커이다.
- 구글 클라우드 Pub/Sub은 비슷하지만, 다른 방식이다. (JMS 형식)
로그 기반 메시지 브로커의 이점
- 초당 수백만 개의 메시지를 처리할 수 있다.
- 메시지를 복제함으로써 장애에 대비할 수 있다.
로그 방식과 전통적인 메시지 방식의 비교
로그 기반 접근법
- 팬 아웃 메시징 방식을 제공한다.
- 소비자가 서로 영향 없이 독립적으로 로그를 읽을 수 있고, 메시지를 읽어도 로그에서 삭제되지 않는다.
- 개별 메시지를 소비자 클라이언트에 할당하지 않고, 소비자 그룹 간 로드 밸런싱한다.
- 브로커는 소비자 그룹의 노드들에 전체 파티션을 할당할 수 있다.
로그 기반 접근법의 장단점
- 장점
- 메시지 처리 속도가 빠르다.
- 메시지 순서가 중요하다면 효과적이다.
- 단점
- 메시지 처리 비용이 비싸다.
- 메시지 순서가 중요하지 않다면 JMS/AMQP 방식의 메시지 브로커가 더 적합하다.
소비자 오프셋
오프셋의 이점
- 파티션 하나를 순서대로 처리하면 메시지를 어디까지 처리했는지 알기 쉽다.
- 메시지마다 보내는 확인 응답을 추적할 필요가 없다.
- 추척 오버헤드가 감소하고 일괄 처리와 파이프라이닝을 수행 할 수 있는 기회를 제공하여 처리량을 늘리는데 도움을 준다.
데이터베이스와 유사점
- 단일 리더 데이터베이스 복제에서 널리 쓰이는 로그 순차 번호와 상당히 유사하다.
- 데이터베이스 복제에서 팔로워가 리더와 연결이 끊어졌다가 다시 접속할 때, 로그 순자 번호를 사용한다.
- 로그 순차 번호를 사용하면 기록을 누락하지 않고 복제를 재개할 수 있다.
- 메시지 브로커는 데이터베이스의 리더처럼 동작하고, 소비자는 팔로워처럼 동작한다.
소비자 노드 장애 발생시 문제점
- 소비자 노드가 장애가 발생하면 그룹내 다른 노드가 오프셋부터 메시지를 처리한다.
- 장애가 발생한 소비자가 처리하였지만, 오프셋이 기록되지 않았다면 두번 처리하게 된다. (이 문제는 후반부에서 다룬다.)
디스크 공간 사용
로그가 점차 쌓이게 되면, 결국 디스크를 전부 사용하게 된다.
디스크를 재사용하기 위해서는 로그를 여러 조각으로 나누고 오래된 조각은 삭제하거나 보관 저장소로 이동한다.
소비자 처리 속도가 느려 생산되는 속도를 따라 잡지 못하면 소비자의 오프셋은 이미 삭제한 조각을 가리킬 수 있다. 즉, 메시지 일부를 잃어버릴 가능성 있다는 뜻이다.
로그는 크기가 제한 된 버퍼로 구현하고 오래된 메시지는 순서대로 버린다. 이를 원형 버퍼(circuler buffer), 링 버퍼(ring buffer)라고 한다.
소비자가 생성자를 따라갈 수 없을 때
소비자가 로그의 헤드로부터 얼마나 떨어졌는지 모니터링하면 눈에 띄게 뒤쳐지는 경우에는 이를 경고를 한다.
운영자는 소비자 처리가 느린 문제를 고쳐 메시지를 잃기 전에 따라 잡을 시간을 충분히 벌 수 있다.
어떤 소비자가 너무 뒤쳐져서 메시지를 읽기 시작해도 해당 소비자만 영향을 받고 다른 소비들의 서비스를 망치지는 않는다.
오래된 메시지 재생
메시지 브로커 비교
- AMQP, JMS 유형의 메시지 브로커
- 메시지를 처리하고 확인 응답하는 작업은 브로커에서 메시지를 제거하기 때문에 파괴 연산을 한다.
- 로그 기반 메시지 브로커
- 메시지를 소비하는게 오히려 파일을 읽는 작업과 더 유사한데 로그를 변화시키지 않는 읽기 전용 연산을 한다.
로그 기반의 이점
메시지 재처리는 몇번이든지 처리 코드를 변경해 재처리가 가능하다.
데이터베이스와 스트림
메시지 브로커 데이터베이스의 관계
- 로그 기반 브로커는 데이터베이스에서 아이디어를 얻어, 메시징에 적용하는데 성공
- 로그 기반 브로커의 메시징 스트림에서 아이디어를 얻어 데이터베이스에 적용
시스템 동기화 유지하기
이중 기록(dual write)
- 주기적으로 데이터베이스 전체를 덤프하는 작업이 너무 느리면 대안으로 사용하는 방법
- 이중 기록을 사용하면 데이터가 변할 때마다 애플리케이션 코드에서 명시적으로 각 시스템에 기록
- 데이터베이스에 기록
- 검색 색인을 갱신
- 캐시 엔트리 무효화
이중 기록의 심각한 문제
각 클라이언트가 동시에 아이템 X를 업데이트하려고 할때, 타이밍 문제로 데이터가 맞지 않게 될 수 있다.
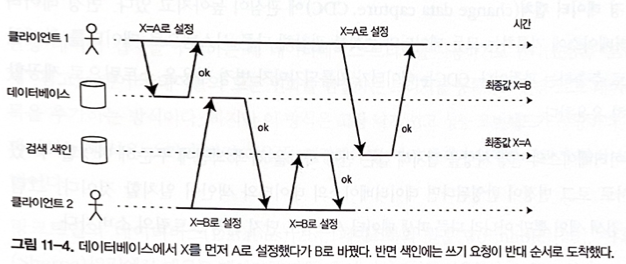
그림 11-4. 데이터베이스에서 X를 먼저 A로 설정했다가 B로 바꿨다. 반면 색인에는 쓰기 요청이 반대 순서로 도착했다.
- 동시성 문제
- “동시 쓰기 감지"에서 설명한 버전 벡터와 같은 동시성 감지 매커니즘을 따로 사용하지 않으면 동시에 쓰기 발생해도 알아 차리지 못한다.
- 내결함성 문제
- 한쪽 쓰기가 성공할 때 다른 쪽 쓰기는 실패할 수 있다.
- 두 시스템 간에 불일치가 발생하는 현상이 발생한다.
- 동시성 또는 동시 실패 보장하는 방식은 원자적 커밋 문제다. 11- 이 문제를 해결하는 데는 비용이 많이 든다.
각 시스템의 단일 리더
- 단일 리더 복제 데이터베이스 하나를 사용한다면 리더가 쓰기 순서를 결정한다.
- 각각 데이터베이스, 검색 색인에 리더를 만들어도 충돌 발생이 여지가 있다.
시스템의 통합 리더
- 색인용 인덱스를 데이터베이스의 팔로워로 만들어 실제 리더를 하나만 존재하게 하면 훨씬 낫다.
변경 데이터 캡처
예전 데이터베이스
- 데이터베이스에서 복제 내용을 가져오려면 데이터 모델과 질의 언어를 통해서 데이터베이스에 직접 질의한다.
- 데이터 내부 상세 구현으로 생각되어 공개 API 자체를 제공하지 않았다.
- 복제 로그를 파싱해서 데이터를 추출하는 방식을 사용하지 못하였다.
- 데이터 베이스에서 발생하는 데이터 변화를 감지해서 변경된 내용을 다른 저장소에 복제하는데 어려움이 있었다.
- 저장소) 검색 색인, 캐시, 데이터 웨어하우스
변경 데이터 캡처(change data capture, CDC)
- 데이터베이스에 기록하는 모든 데이터의 변화를 관찰해 다른 시스템으로 데이터를 복제할 수 있다는 추출 과정이다.
- 데이터가 기록되자마자 변경 내용을 스트림으로 제공에 유용
- 데이터베이스의 변경 사항을 캡처해 같은 변경 사항을 검색 색인에 꾸준히 반영할 수 있다.
- 같은 순서로 로그 변경이 반영된다면 데이터베이스의 데이터와 색인이 일치할 것이다.
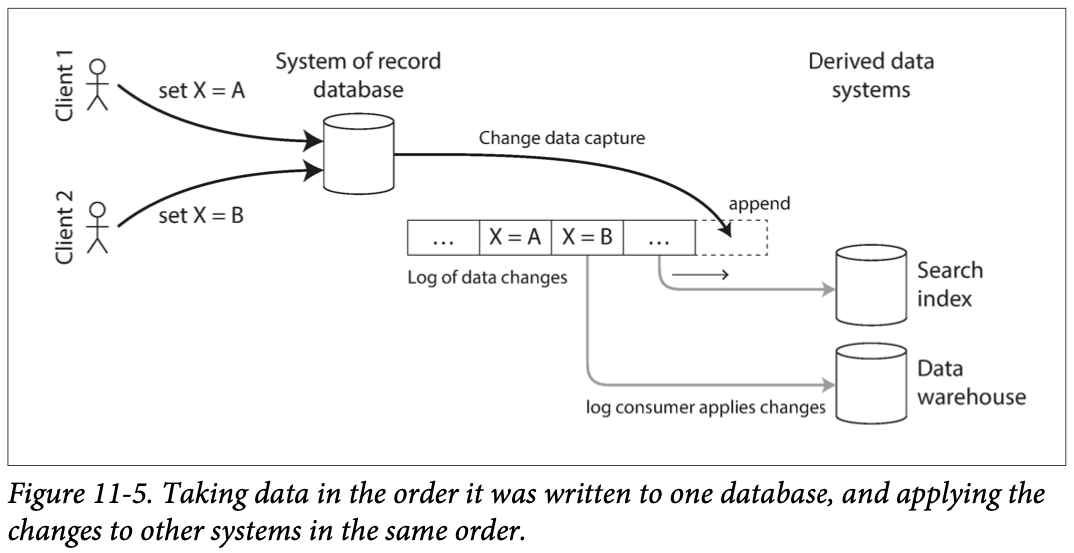
그림 11-5. 데이터베이스에 쓰여진 순서대로 데이터를 가져와 다른 시스템에 변경 사항을 같은 순서로 적용한다.
변경 데이터 캡처의 구현
파생 테이터 시스템
- 검색 색인과 데이터 웨어하우스에 저장된 데이터는 레코드 시스템에 저장된 데이터의 또 다른 뷰일 뿐이므로 로그 소비자이다.
변경 데이터 캡처
- 파생 데이터 시스템이 레코드 시스템의 정확한 데이터 복제본을 가지게 하기 위해 레코드 시스템에 발생하는 모든 변경 사항을 파생 데이터 시스템에 반영하는 것을 보장하는 메커니즘이다.
- 본질적으로 변경 사항을 캡처할 데이터베이스 하나를 리더로 하고 나머지를 팔로워로 한다.
- 로그 기반 메시지 브로커는 원본 데이터베이스에서 변경 이벤트를 전송하기에 적합하다.
- 메시지를 순서를 유자하기 때문이다.
변경 데이터 캡처의 구현
- 데이터베이스 트리거를 사용하는 방식
- 데이터 테이블의 모든 변화를 관찰하는 트리거를 등록하고 변경 로그 테이블에 해당 항목 추가하는 방식이다.
- 단점으로, 고장 나기 쉽고 선능 오버헤드가 상당하다.
- 복제 로그를 방식하는 방식
- 단점으로 스키마 변경 대응 등 해결해야 할 문제 있다.
- 트리거 방식보다 견고한 방법이다.
변경 데이터 캡처의 종류
- PostgreSQL용 CDC
- 보틀드 워터(Bottled Water)는 쓰기 전 로그를 복호화하는 API를 사용한다.
- MySQL용 CDC
- 맥스웰(Maxwell), 디비지움(Debezium)은 binlog를 파싱 방식으로 구현한다.
- MongoDB용 CDC
- 몽고리버(Mongoriver)는 oplog를 읽는다.
- 오라클용 CDC
- 골드게이트(GoldenGate)도 oplog를 읽는것과 비슷하다.
변경 데이터 캡처의 동작
- 비동기 방식으로 동작한다.
- 장점
- 데이터베이스는 변경 사항을 커밋하기 전에 변경 사항이 소비자에게 적용될 때가지 기다리지 않는다.
- 느린 소비자가 추가되어도 시스템에 미치는 영향이 적다.
- 단점
- 복제 지연의 모든 문제가 발생한다.
초기 스냅숏
데이터베이스 변경 로그
- 데이터베이스에서 발생한 모든 변경 로그가 있다면 로그를 재현해서 데이터베이스의 전체 상태를 재구축할 수 있다.
- 모든 변경 사항을 영구적으로 보관하기에는 디스크 공간이 많이 필요하다.
- 모든 로그를 재생하는 작업도 너무 오래 걸린다.
- 그래서 로그를 적당히 잘아야 한다.
스냅숏의 필요성
- 전문 색인을 새로 구축할 때를 예로 들면 전체 데이터베이스 복사본이 필요하다.
- 최근한 갱신하지 않은 항목은 로그에 없기 땜누에 최근 변경 사항만 반영하는 것으로는 충분하지 않다.
- 이때 일관성 있는 스냅숏을 사용해야 한다.
스냅숏의 기능
- 변경 로그의 위치나 오프셋에 대응돼야 한다.
- 그래야 스냅숏 이후에 변경 사항을 적용할 시점을 알 수 있다.
로그 컴팩션
로그 히스토리의 양을 제한한다면 새로운 파생 데이터 시스템을 추가할 때마다 스냅숏을 만들어야 한다.
로그 컴팩션 동작 원리
- 저장 엔진은 주기적으로 같은 키의 로그 레코드를 찾아 중복 제거한다.
- 각 키에 대한 가장 최근에 갱신된 내용만 유지한다.
- 컴팩션 병합 과정은 백그라운드로 실행한다.
톰스톰(tombstone, 묘비)
- 키의 삭제를 의미하고, 컴팩션을 수행할 때 실제로 값을 제거한다.
- 키를 덮어쓰거나 삭제하지 않는 한 영구적으로 유지한다.
- 현재 데이터베이스에 있는 최신 값이 필요하다.
로그 기반 메시지 브로커
- CDC 시스템에서 모든 변경에 기본키가 포함되게 하고
- 키의 모든 갱신이 해당 키의 이전 값을 교체한다면 특정 키에 대한 최신 쓰기만 유지하면 충분하다.
변경 스트림용 API 지원
변경 스트림 인터페이스 제공하기 시작….리버스 엔지니어링 이런거 안함
- 리싱크DB(RethinkDB)
- 질의 결과에 변경이 있을 때 알림을 받을 수 있게 구독이 가능한 절의를 지원한다.
- 파이어베이스(FireBase)와 카우치DB(CouchDB)
- 애플리케이션에도 사용 가능한 변경 피드 기반의 데이터 동기화를 지원한다.
- 미티어(Meteor)
- 몽고DB의 oplog를 사용해 데이터 변경사항을 구독하거나 사용자 인터페이스를 갱신
볼트DB(VoltDB)
- 스트림 형태로 데이터베이스에세 데이터를 지속적으로 내보내는 트랜잭션을 제공한다.
카프카 커넥트(Kafka Connect)
- 카프카를 광범위한 데이터 시스템용 변경 데이터 캡처 도구로 활용하기 위한 노력의 일환이다.
- 변경 이벤트를 스트림하는데 카프카를 사용하면 검색 색인과 같은 파생 데이터 시스템을 갱신하는데 사용 가능하다.
이벤트 소싱
이벤트 소싱(event sourcing)
- 도메인 주도 설계(domain-driven design, DDD) 커뮤니티에서 개발한 기법이다.
- 애플리케이션 상태 변화를 모두 변경 이벤트 로그로 저장한다.
- 변경 데이터 캡처와 유사하다.
- 변경 데이터 캡처와 큰 차이점은 추상화 레벨이 다르다.
- 추상화 레벨이란?
이벤트 데이터 캡처와 이벤트 소싱 차이점
- 이벤트 데이터 캡처
- 애플리케이션은 데이터베이스를 변경 가능한 방식으로 사용해 레코드를 자유롭게 갱신하고 삭제한다.
- 추가(O) 갱신(O), 삭제(O)
- 변경 로그는 데이터베이스에서 추출한 쓰기 순서가 실제로 데이터를 기록한 순서와 일치한다.
- 데이터베이스에 기록한 애플리케이션은 CDC가 실행 중인지 알 필요가 없다.
- 애플리케이션은 데이터베이스를 변경 가능한 방식으로 사용해 레코드를 자유롭게 갱신하고 삭제한다.
- 이벤트 소싱
- 애플리케이션 로직은 이벤트 로그에 기록된 불변 이벤트를 기반으로 명시적으로 구축한다.이는 단지 추가만 가능하고 갱신이나 삭제는 권장하지 않거나 금지한다는 것의 의미한다.
- 추가(O) 갱신(X), 삭제(X)
- 이벤트는 저수준에서 상태 변경을 반영하는 것이 아니라 애플리케이션 수준에서 발생한 일을 반영하게끔 설계 됐다.
- 애플리케이션 로직은 이벤트 로그에 기록된 불변 이벤트를 기반으로 명시적으로 구축한다.이는 단지 추가만 가능하고 갱신이나 삭제는 권장하지 않거나 금지한다는 것의 의미한다.
이벤트 소싱의 이점
- 데이터 모델링에 쓸 수 있는 강력한 기법이다.
- 애플리케이션 관점에서 사용자의 행동을 불변 이벤트로 기록하는 방식
- 애플리케이션을 지속해서 개선하기가 매우 유리하다.
- 디버깅에 도움이 되고, 애플리케이션 버그를 방지한다.
- 이벤트 소싱 접근법을 사용하며 새로 발생한 부수 효과를 기존 이벤트에서 쉽게 분리할 수 있다.
이벤트 로그에서 현재 상태 파생하기
유용하지 않은 이벤트 로그
사용자 시스템의 현재 상태를 보기 원하지, 수정 히스토리를 모두 보고 싶어하지는 않는다.
예를 들면, 쇼핑 사용자는 장바구니의 모든 변경 사항이 아닌 현재 상태만 보고 싶어 한다.
이벤트 로그 변환 작업
따라서, 시스템에 기록한 데이터를 표현한 이벤트 로그를 가져와 사용자에서 보여주기 적당히 변화해야 한다.
변화 과정은 로직을 자유롭게 사용할 수 있지만, 다시 수행하더라도 이벤트 로그로부터 동일한 애플리케이션 상태를 만들 수 있어야 한다.
이벤트 로그 컴팩션 불가능
- CDC 이벤트
- 기본키의 현재 값은 전적으로 기본키의 가장 최신 이벤트로 결정된다.
- 같은 키의 이벤트는 이전 이벤트로 덮어 쓰는것이 가능하기에 로그 캠팩션이 가능하다.
- 이벤트 소싱
- 마지막 상태를 재구축하기 위해서는 이벤트 전체 히스토리가 필요하다.
- 이벤트는 사용자 행동의 결과로 발생한, 상태 메커니즘이 아닌 사용자 행동 의도를 표현하기 때문이다.
- 그래서, 로그 컴팩션 불가능 하다.
- 마지막 상태를 재구축하기 위해서는 이벤트 전체 히스토리가 필요하다.
이벤트 소싱 한계점
이벤트 로그 기반의 현재 상태의 스냅숏을 저장하는 매커니즘이 있기에, 매번 전체 로그를 재처리할 필요는 없다.
그러나, 이는 장애 발생 시 읽고 복구하는 선능을 높여주는 최적화가 불과하다.
이벤트 소싱 시스템은 모든 원시 이벤트를 영원히 저장하고 필요할 때마다 모든 이벤트를 재처리 할 수 있어야 한다.
명령과 이벤트
명령(command)이란?
사용자 요청이 처음 도착했을 때 이 요청은 명령이다. 특정 무결성 조건을 위반하면 실패한다.
무결성이 검증되고 명령이 승인 되면 지속성 있는 불변 이벤트가 된다.
이벤트 불변
이벤트가 한번 생성되면 사실(fact)가 된다.
다시 변경 및 취소가 되었더라고 기존 정보는 여전히 사실로 남아 있으며, 다시 변경 및 취소는 나중에 추가된 독립적인 이벤트가 된다.
이벤트 스트림 소비자 소비자는 이벤트를 거절 못한다. 이벤트를 받은 시점에는 이벤트는 이미 불변 로그의 일부분이다. 명령 유효성은 이벤트가 되기 전에 동식으로 검증해야 한다. 이를테면 직렬성 트랜잭션을 사용해 원자적으로 명령을 검증하고 이벤트를 발행 할 수 있다.
사용자 요청 이벤트 두개로 분할하면 비동기 처리를 유효성 검사를 할 수 있다.
- 예를 들면,
- 사전 예약(가예약)
- 예약 확정(유효한 예약)
상태와 스트림 그리고 불변성
입력 파일의 불변성이 주는 이점
- 입력 파일에 손상을 주지 않고 기존 입력 파일에 얼마든지 실험적 처리 작업을 수행할 수 있다.
- 불변성 원리가 이벤트 소싱과 변경 데이터 캡처를 매우 강력하게 만든다.
불변 이벤트의 장점
회계 장부
- 거래(트랜잭션)가 발생하면 거래 정보를 원장(ledger)에 추가만 하는 방식으로 기록한다.
- 원장은 본질적으로 돈, 상품, 서비스를 교환 정보를 설명한 이벤트 로그다.
- 실수가 발생해도 원장의 잘못된 거래 내역을 지우거나 고치지 않고, 영원이 남는다.
- 틀린 원장으로부터 만든 수치가 이미 발표됐다면, 다음 회계 기간에 수정한다.
- 이는 회계 감사에 중요한 사유가 될 수 있다.
버그로 인해 잘못된 데이터가 발생했을 때,
- 데이터베이스 : 잘못된 데이터를 기록되었다면, 복구가 매무 어렵다.
- 불변 이벤트 로그 : 추가만 하는 로그를 썼다면 문제 상황 진단과 복구가 훨씬 쉽다.
불변 이벤트를 통한 유용한 정보
쇼핑 웹사이트에서 고객이 장바구니에 항목 하나를 넣었다가 제거 했을 때
- 주문 이행 관점
- 단순 두번째 이벤트(제거)는 단지 첫번 이벤트(추가)를 취소했을 뿐이다.
- 분석가의 관점
- 고객이 나중에 구매하려고 했거나, 대체제를 찾았을 것을 뜻한다.
이런 유용한 정보는 이벤트 로그에는 기록되지만, 데이터베이스에서는 장바구니에서 항목을 제거 했을 잃어버리는 정보가 된다.
동일한 이벤트 로그로 여러 가지 뷰 만들기
불변 이벤트 로그에서 가변 상태로 분리하면, 동일한 이벤트 로그로 여러 읽기 전용 뷰를 만들 수 있다.
- 분석 데이터베이스 드루이드(Druid) : 카프카로부터 직접 데이터를 읽어 처리
- 피스타치오(Pistachio) : 분산 키-값 저장소로 카프카를 커밋 로그처럼 사용
- 카프카 커넥트 싱크(Kafka Connect Sink): 카프카에서 여러 데이터베이스와 색인에 데이터를 내보낼 수 있다.
기존 데이터를 새로운 방식으로 표현하는 새 기능을 추가하려면 이벤트 로그를 사용해 신규 기능용으로 분리한 읽기 최적화된 뷰를 구축할 수 있다.
- 기존 시스템을 수정할 필요가 없고 기존 시스템과 함께 운용이 가능하다.
- 신구 시스템을 나란히 구동하는 것은 기존 시스템에서 복잡한 스키마 이전을 수행하는 것보다 쉽다.
명령 질의 책임의 분리(command query responsibility segregation, CQRS)
- 데이터를 어떻게 질의하고 접근하는지 신경 쓰지 않는다면, 데이터 저장은 상당히 직관적인 작업이다.
- 데이터를 쓰는 형식, 읽는 형식을 분리해 다양한 읽기 뷰를 혀용한다면 상당한 유연성을 얻을 수 있다.
기존 아키텍쳐에서 점차 CQRS 패턴이 구현되는 모습. 마지막 단계에서 RDBMS와 NoSQL 간 데이터 이동은 Kafka와 같은 메시지 큐가 적용될 수 있다.
읽기 최적화된 뷰의 비정규화
- 데이터베이스와 스키마 설계의 전통적인 접근법은 데이터를 질의 받게 될 형식과 같은 형식으로 데이터를 기록해야 한다는 잘못된 생각에 기초한다.
- 데이터를 쓰기 최적화된 이벤트 로그에서 읽기 최적화된 애플리케이션 상태로 전환 가능하면 정규화와 비정규화에 관한 논쟁은 의미 없다.
- 읽기 최적화된 뷰는 데이터를 비정규화하는 것이 전적으로 합리적이다.
동시성 제어
이벤트 소싱과 변경 데이터 캡처의 가장 큰 단점은 이벤트 로그의 소비가 대개 비동기로 이뤄진다는 점이다.
- 사용자가 로그에 이벤트를 기록하고, 이어서 파생된 뷰를 읽어도 기록한 이벤트가 뷰에 반영되지 않았을 가능성이 있다.
해결책으로 하나는 읽기 뷰의 갱신과 로그에 이벤트를 추가하는 작업을 동기식으로 수행하는 방법이다.
- 이 방법을 쓰려면 트랜잭션에서 여러 쓰기를 원자적 단위로 결합해야 하므로 이벤트 로그와 읽기 뷰를 같은 저장 시스템에 담아야 한다.
반면 이벤트 로그를 현재 상태로 만들면 동시성 제어 측면이 단순해진다.
- 다중 객체 트랜잭션은 단일 사용자 동작이 여러 다른 장소의 데이터를 변경해야 할 때 필요하다.
- 그러면 사용자 동작은 한 장소에서 한 번 쓰기만 필요하다. 즉, 이벤트를 로그에 추가만 하면 되며 원자적으로 만들기 쉽다.
이벤트 로그와 상태를 같은 방식으로 파티셔닝하면, 간단한 단일 스레드 로그 소비자는 쓰기용 동시성 제어는 필요하지 않다.
불변성의 한계
데이터 유지는 어디 정도까지 가능할까?
- 데이터 셋이 뒤틀리는 양에 따라 다르다.
- 매우 비번히 갱신과 삭제를 하는 작업부하는 불변 히스토리가 감당하기 힘들 정도로 커지거나 파편화 문제가 발생할 수도 있다.
- 컴팩션과 가비지 컬렉션의 선능 문제가 견고한 운영을 하는데 큰 골치거리가 되기도 한다.
데이터 삭제해야 할 경우가 있다.
- 선능적인 이유로 데이터를 삭제해야 하는 경우가 있다.
- 개인 정보 및 민감한 정보를 삭제해야 하는 경우도 있다.
데이터를 진짜로 삭제하는 작업은 어렵다.
- 많은 곳에 복제본이 남아 있기 때문이다.
- 삭제는 해당 데티러를 “찾기 불가능하게끔"하는 문제라기보다는 “찾기 어렵게"하는 문제이다.
스트림 처리
- 스트림을 처리하는 방법
- 이벤트에서 데이터를 꺼내 데이터베이스나 캐시,검색 색인 또는 유사한 저장소 시스템에 기록하고, 다른 클라이언트가 이 시스템에 해당 데이터를 질의한다.
그림 11-5. 데이터베이스에 쓰여진 순서대로 데이터를 가져와 다른 시스템에 변경 사항을 같은 순서로 적용한다. - 이벤트를 사용자에게 직접 보낸다.
- 이메일 경고, 푸시 알림, 실시간 대시보드
- 하나 이상의 입력 스트림을 처리해 하나 이상의 출력 스트림을 생산한다.
- 스트림 처리자가 입력 스트림을 소비해 추가 전용 방식으로 다른 곳에 출력을 쓴다.
- 이벤트에서 데이터를 꺼내 데이터베이스나 캐시,검색 색인 또는 유사한 저장소 시스템에 기록하고, 다른 클라이언트가 이 시스템에 해당 데이터를 질의한다.
- 스트림을 처리하는 코드 조각을 연산자(operator)나 작업(job)이라 부른다.
스트림 처리의 사용
모니터링 시스템
- 특정 상황이 발생하면 경고를 해주는 모니터링 목적으로 사용돼 왔다.
- 사기 감시 시스템의 신용카드 사용 패턴
- 금융 시장의 가격 변화 감지
- 공장의 기계 상태 모니터링: 오작동 감지
- 군사 첩보 시스템의 잠재적 침략자의 활동 추적
복잡한 이벤트 처리
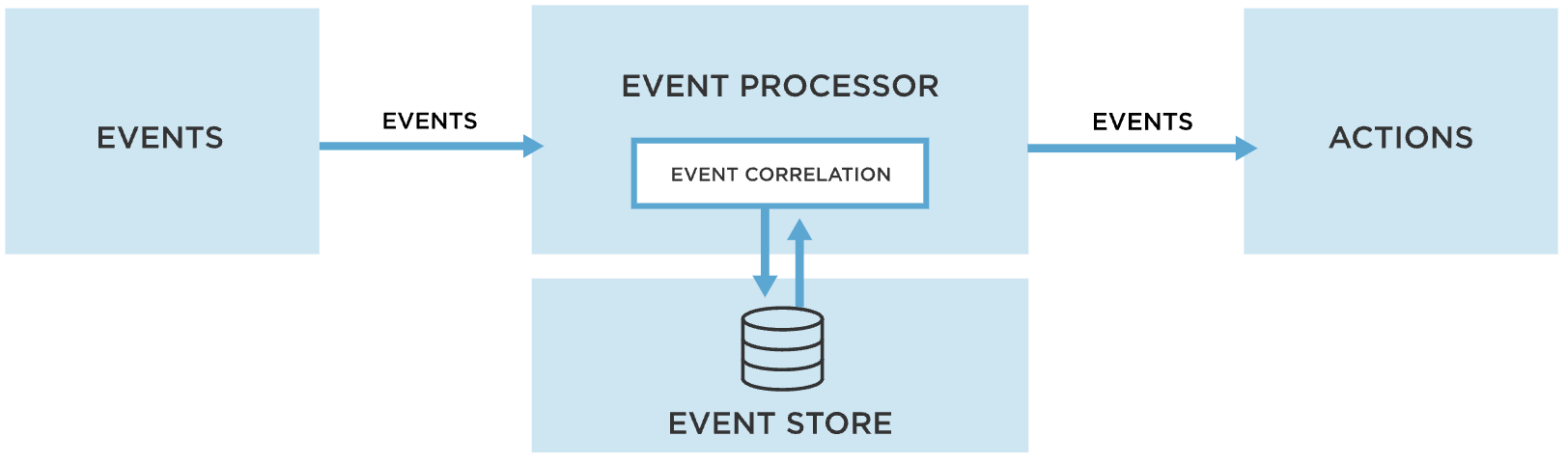
- 복잡한 이벤트 처리(complex event processing, CEP)
- 특정 이벤트 패턴 검색에 적합
- 정규 표현식으로 문자열에서 특정 문자 패턴을 찾는 방식과 유사함
- 질의는 처리 엔진에 제출하고 처리 엔진은 입력 스트림을 소비해 필요한 매칭을 수행하는 상태 기계를 내부적으로 유지한다.
- 해당 매치를 발견하면 엔진은 감지한 이벤트 패턴의 세부 사항을 포함하는, 글자 그대로 복잡한 이벤트(complex event)를 방출한다.
데이터베이스와 비교
| 구분 | 데이터베이스 | CEP |
|---|---|---|
| 데이터 저장 형태 | 영구 저장 | 흘러가면서 이벤트 패턴에 매칭되는 질의를 찾음 |
| 질의 형태 | 일시적 | 오랜 기간 저장 |
스트림 분석
- 스트림 분석은 대량의 이벤트를 집계하고 통계적 지표를 뽑는다.
- 특정 유형의 이벤트 빈도 측정
- 특정 기간에 걸친 값의 이동 평균(rolling average) 계산
- 이전 시간 간격과 현재 통계값의 비교
- 통계는 고정된 시간 간격 기준으로 계산한다. 집계 시간 간격을 윈도우(window)라 한다.
- ex)
- 지난 5분간 서비스에 들어온 초당 질의 수의 평균을 구하거나
- 같은 기간 동안의 99분위 응답 시간을 구한다.
- ex)
구체화 뷰 유지하기
- 데이터베이스 변경에 대한 스트림은 파생 데이터 시스템이 원본 데이터베이스의 최신 내용 동기화.
- 파상 데이터 시스템: 캐시, 검색 색인, 데이터 웨어하우스
- 어떤 데이터셋에 대한 또 다른 뷰를 만들어 효율적으로 질의할 수 있게 하고 기반이 되는 데이터가 변경될 때마다 뷰를 갱신한다.
- 이벤트 소싱에서 애플리케이션 상태는 이벤트 로그를 적용함으로써 유지된다.
- 애플리케이션 상태는 일종의 구체화 뷰
스트림 상에서 검색하기
복잡한 기준을 기반으로 개별 이벤트를 검색해야 하는 경우
- 부동산 웹사이트의 사용자는 부동산 시장에 사용자가 설정한 검색 기준과 매칭되는 새 부동산이 나오면 알려달라고 요청할 수 있다
- 스트림 검색: 질의를 먼저 저장하고 문서는 질의를 지나가면서 실행된다. (CEP)
- 전통적인 검색 엔진: 문서를 색인하고 색인을 통해 질의
메시지 전달과 RPC
- 메시지 전달 시스템을 RPC 대안으로 사용할 수 있다.
- 아파치 스톰: DRPC(Distributed RPC)
시간에 관한 추론
- 분석 목적으로 스트림을 처리하는 경우 시간을 다뤄야 할 때가 있다.
- ex) 지난 5분 동안 평균(윈도우)
- 스트림 처리 프레임워크는 윈도우 시간을 결정할 때 처리하는 장비의 시스템 시계(처리 시간)를 이용한다.
- 이벤트 생성과 처리 사이의 간격을 확인하여 문제 발생을 예측할 수 있다.
- 일괄 처리는 이벤트에 내장된 타임스탬프 이용
이벤트 시간 vs 처리 시간
- 처리가 지연되는 이유
- 큐 대기
- 네트워크 결함
- 메시지 브로커나 처리자에서 경쟁을 유발하는 성능 문제
- 스트림 소비자의 재시작
- 결함에서 복구하는 도중이나 코드 상의 버그를 고친 후 과거 이벤트의 재처리
- 이벤트 발생 시간과 처리 시간을 혼동하면 잘못된 데이터가 생길 수 있다.
- 스트림 처리자가 재시작한 상황: 1분간 스트림 처리가 셧다운됐다가 복구되어 백로그 이벤트를 처리
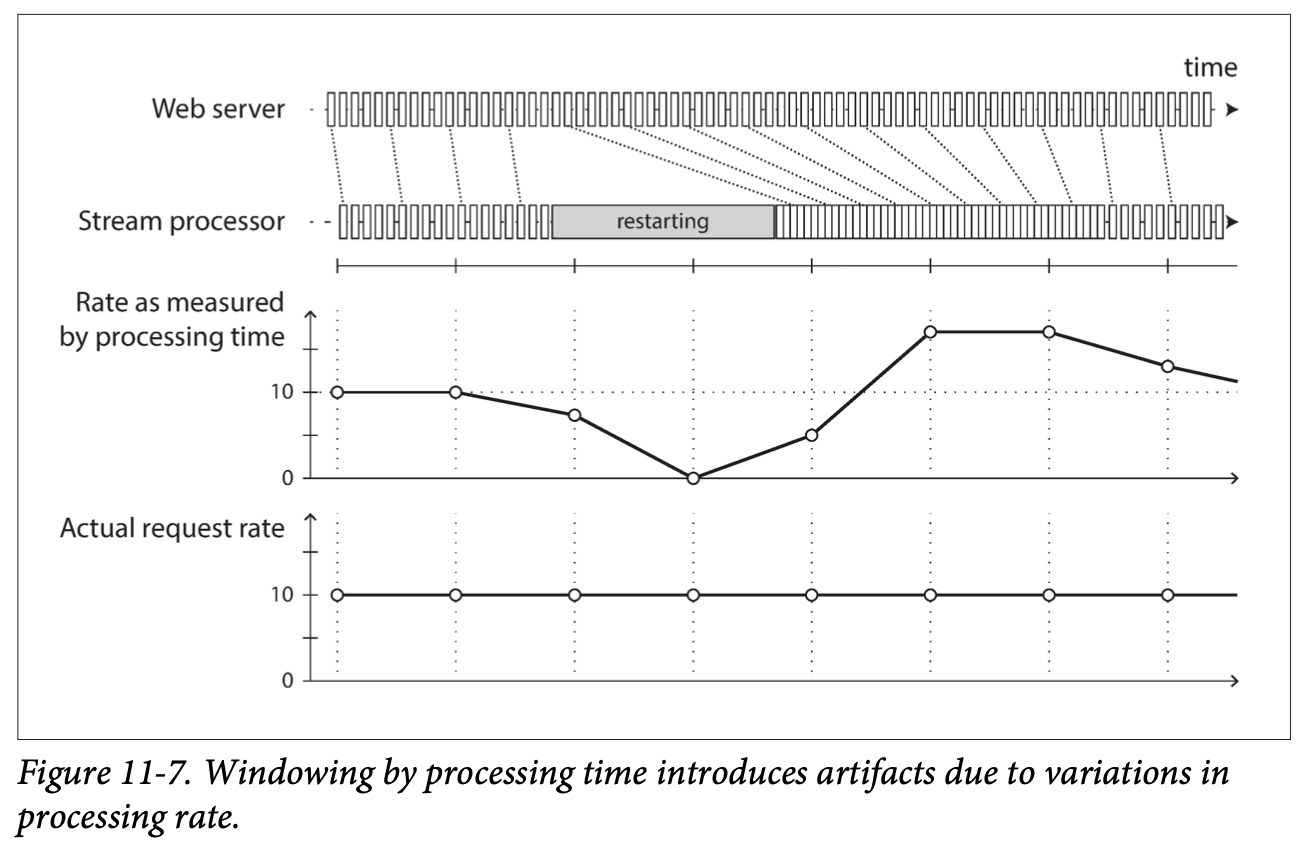
그림 11-7. 처리 시간 기준으로 윈도우를 만들면 처리율의 변동 때문에 생기는 허상을 남긴다.
준비 여부 인식
- 이벤트 시간 기준으로 윈도우를 정의할 때 낙오자(straggler)가 발생할 수 있다.
- 낙오자 이벤트를 처리하는 방법
- 낙오자 이벤트는 무시한다. 적은 비율일 때 무시하지만, 비율이 높아지면 알림을 보내는 방법으로 처리
- 수정 값을 발행한다. 이벤트가 포함된 윈도우를 기준으로 새로 갱신한 값
어떤 시계를 사용할 것인가?
이벤트가 발생한 머신과 이벤트를 처리하는 서버의 시간을 통해서 이벤트 발생 시간을 추정하는 방법(잘못된 장치 시계를 조정하는 방법)
세 가지 타임스탬프를 로그로 남긴다
- 이벤트가 발생한 시간(장치 시계)
- 이벤트를 서버로 보낸 시간(장치 시계)
- 서버에서 이벤트를 받은 시간(서버 시계) 두 번째와 세 번째의 차이를 구하면 장치 시계와 서버 시계 간의 오프셋을 추정할 수 있다.
필요한 타임스탬프 정확도에 비해 네트워크 지연은 무시할 만하고 계산한 오프셋을 이벤트 타임스탬프에 적용해 이벤트가 실제로 발생 시간을 추정할 수 있다
윈도우 유형
이벤트 타임스탬프를 어떻게 결정할지 안다면 다음 단계는 윈도우 기간을 어떻게 정의해야 하는지 결정하는 일이다.
이벤트 수를 세거나 윈도우 내 평균값을 구하는 등 집계할 때 사용한다.
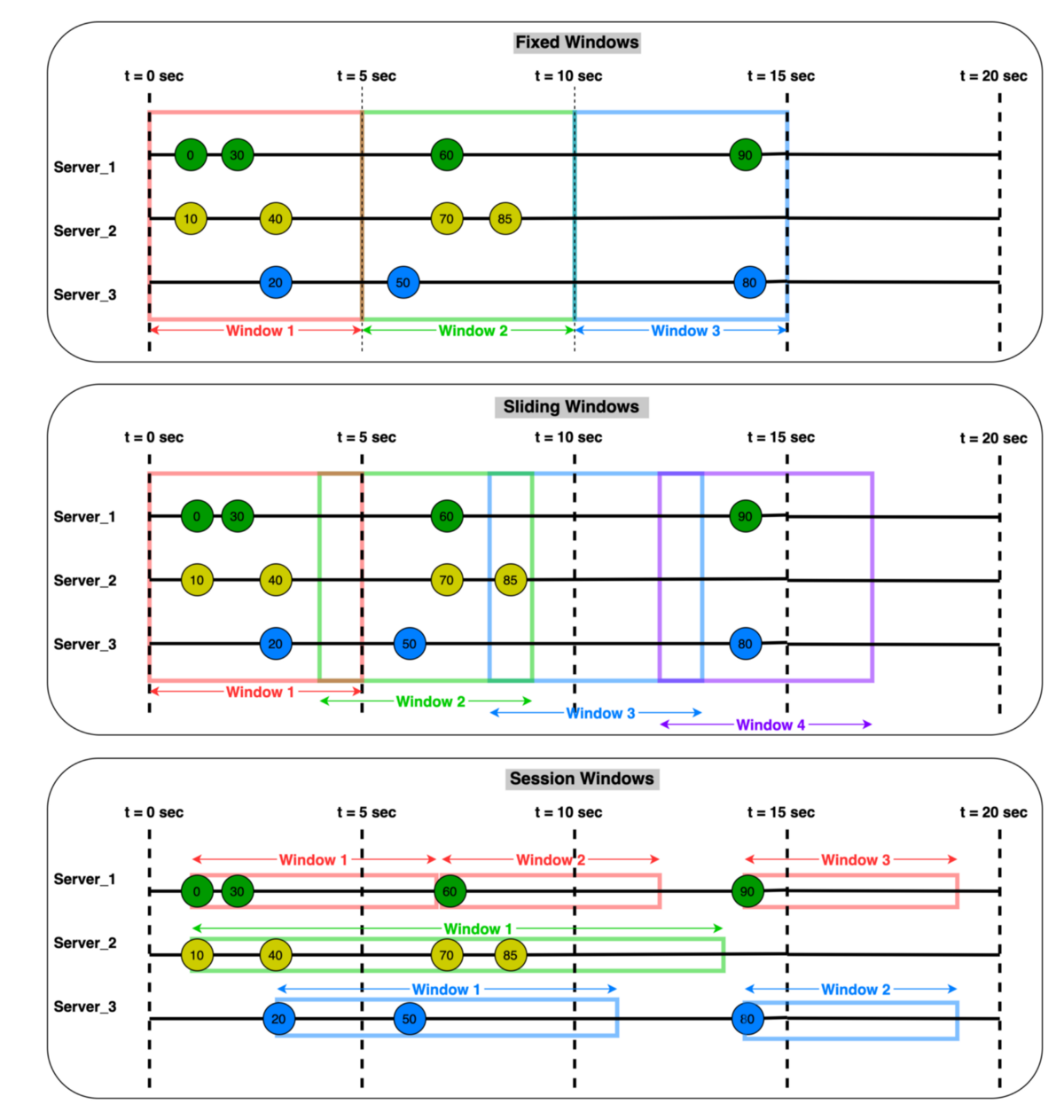
- 텀블링 윈도우(Tumbling window)
- 고정 길이
- 겹치는 부분 없음
- 홉핑 윈도우(Hopping window)
- 고정 길이
- 겹치는 부분 있음
- 슬라이딩 윈도우(Sliding window)
- 고정 길이
- 이벤트 timestamps 에 따라 겹칠 수도 있고, 겹치지 않을 수도 있음
- 세션 윈도우(Session window)
- 동적 변동 길이
- 데이터 기반 윈도
스트림 조인
일괄 처리 작업과 비슷하다.
하지만, 스트림 상에서 새로운 이벤트가 언제든 나타날 수 있다는 사실은 스트림 상에서 수행하는 조인을 일괄 처리 작업에서 수행하는 조인보다 어렵게 만든다.
스트림 스트림 조인(윈도우 조인)
그림. 윈도우 크기: 10초
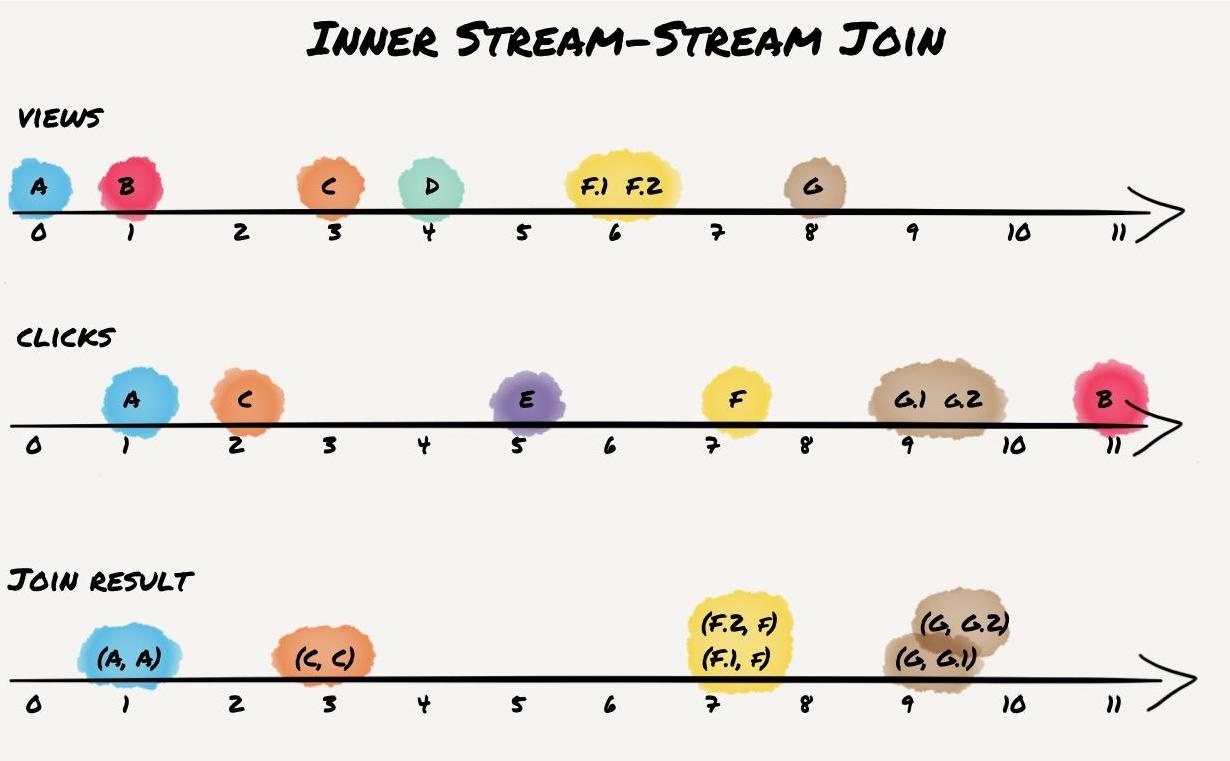
- ex) 웹사이트에 검색 기능이 있고 검색된 URL의 최신 경향을 파악하고 싶다.
- 검색 질의 타이핑할 때마다 질의와 반환된 결과가 있는 이벤트를 로깅한다.
- 같은 세션 ID로 서로 연관된 검색 활동 이벤트와 클릭 활동 이벤트를 함께 모은다. (F)
- 검색은 했지만 클릭이 발생하지 않을 수 있다. (D)
- 네트워크 지연도 가변적이기 때문에 클릭 이벤트가 먼저 도착할 수 있다. (E)
- 조인을 위한 적절한 윈도우 선택이 필요하다.
- 스트림 처리자가 상태(state)를 유지해야 한다.
- ex) 지난 시간에 발생한 모든 이벤트를 세션 ID로 색인한다.
- 검색, 클릭 이벤트가 발생할 때마다 해당 색인에 추가하고 스트림 처리자는 같은 세션ID로 이미 도착한 다른 이벤트가 있는지 다른 색인을 확인해야 한다.
- 이벤트가 매칭되면 검색한 결과를 클릭했다고 말해주는 이벤트를 방출한다.
스트림 테이블 조인(스트림 강화)
리스팅개발팀 > 11. 스트림 처리 > stream-table-join.jpg

- 데이터베이스로부터 데이터를 가져와서 이벤트 스트림과 조인
- 네트워크 왕복 없이 스트림 처리자 내부에 데이터베이스 사본을 적재한다.
- 사본 용량에 따라 메모리 내 해시테이블 또는 로컬 디스크에 넣을 수도 있다.
- 복사본을 최신 상태로 유지: 변경 데이터 캡처(change data capture, CDC)
- 스트림 스트림 조인과 비슷하지만, 테이블 변경 로그 스트림쪽은 “시작 시간"까지 이어지는 윈도우를 사용하며 레코드의 새 버전으로 오래된 것을 덮어쓴다 (G1, G2)
테이블 테이블 조인(구체화 뷰 유지)

- 양쪽 입력 스트림이 모두 데이터베이스의 변경 로그다. 한 쪽의 모든 변경을 다른 쪽의 최신 상태와 조인한다.
- 결과를 두 테이블을 조인한 구체화 뷰의 변경 스트림이 된다.
조인의 시간 의존성
- 하나의 조인 입력을 기반으로 한 특정 상태 유지
- 다른 조인 입력에서 온 메시지에 그 상태를 질의한다.
- 상태를 유지하는 이벤트의 순서는 매우 중요하다.
- 시간에 따라 변하는 상태를 조인해야 한다면 어느 시점을 조인에 사용해야 할까?
- ex) 물건 판매: 세율
- 복수 개의 스트림에 걸친 이벤트 순서가 결정되지 않으면 조인도 비결정적이다.
- 천천히 변하는 차원(slowly changing dimension, SCD)
- 조인되는 레코드의 특정 버전을 가리키는 데 유일한 식별자(unique identifier)를 사용해 해결한다.
- 세율이 바뀔 때마다 새 식별자를 부여하고 송장에는 판매 시점의 세율을 표시하는 식별자를 포함해야 한다.
- 이렇게 변경한 조인은 결정적이지만 테이블에 있는 레코드의 모든 버전을 보유해야 하기 때문에 로그 컴팩션이 불가능하다.
내결함성
일괄 처리(10장)는 일부 태스크가 실패할지라도 재처리가 가능하다.
스트림 처리는 무한하다. 그래서 처리를 절대 완료할 수 없다.
마이크로 일괄 처리와 체크 포인트
- 마이크로 일괄처리(microbatching): 스트림을 작은 블록으로 나누고 각 블록을 소형 일괄 처리와 같이 다루는 방법이다.
- 스파크 스트리밍에서 사용
- 처리 크기는 약 1초 정도
- 처리 크기가 작을수록 스케줄링과 코디네이션 비용이 커진다
- 처리 크기가 클수록 스트림 처리의 결과를 보기까지 지연시간이 길어진다
- 체크포인트(checkpoint): 주기적으로 상태의 롤링 체크포인트를 생성하고 지속성 있는 저장소에 저장한다.
- 아파치 플링크
- 스트림 연산자에 장애가 발생하면 스트림 연산자는 가장 최근 체크포인트에서 재시작하고 해당 체크포인트와 장애 발생 사이의 출력은 버린다.
- 두 가지 접근법만으로는 이 문제를 방지하기에 충분하지 않다.
원자적 커밋 재검토
- 장애가 발생했을 때 정확히 한 번 처리되는 것처럼 보일려면 처리가 성공했을 때만 모든 출력과 이벤트 처리의 부수 효과가 발생하게 해야 한다.
- 원자적이거나 동기화되어야함
멱등성(idempotence)
- 결국 목표는 처리 효과가 두 번 나타나는 일 없이 안전하게 재처리하기 위해 실패한 태스크의 부분 출력을 버리는 것
- 멱등 연산: 여러 번 수행하더라도 오직 한 번 수행한 것과 같은 효과를 내는 연산
- 연산 자체가 멱등적이지 않아도 약간의 여분 메타데이터로 연산을 멱등적으로 만들 수 있다.
- 모든 메시지에는 영속적이고 단조 증가하는 오프셋이 있다.
- 트리거한 메시지의 오프셋을 함께 포함한다면 이미 갱신이 적용됐는지 확인할 수 있기 때문에 반복해서 같은 갱신이 수행되는 것을 막을 수 있다.
실패 후에 상태 재구축하기
- 원격 데이터 저장소에 상태를 유지하고 복제하는 것
- 스트림 처리자의 로컬에 상태를 유지하고 주기적으로 복제하는 것
모든 트레이드오프는 기반 인프라스트럭처의 성능 특성에 달려있다.
참조 자료
- 윈도우 : CONFLUENT | Streams DSL | Confluent Documentation
- 스트림 조인 : CONFLUENT | Crossing the Streams – Joins in Apache Kafka