데이터 중심 애플리케이션 설계 | 04장. 부호화 발전
발표자 : 황윤호
애플리케이션은 필연적으로 시간이 지남에 따라 변한다.
새로운 제품을 출시하거나 사용자 요구사항, 비즈니스 환경이 변함에 따라 애플리케이션 기능은 추가하거나 변경된다.
이 변환에 DB의 변화도 포함되고 컬럼, 필드가 추가되거나 삭제되기도 한다.
이러한 DB 관점의 변경은 바로 적용이 가능하다. 하지만, application의 코드는 대체로 바로 적용되지 않는다.
Application 코드가 바로 적용되지 않는 이유
- code의 update 방식은 rolling update 방식으로 진행된다.
- client의 경우 업데이트를 바로 하지 않는 사용자도 있기 때문이다.
호환성
- 하위 호환성
- 새로운 코드는 이전 코드가 기록한 데이터를 읽을 수 있어야 한다.
- 새로운 코드는 기존 데이터에 대해 알기에 큰 문제가 없다.
- 상위 호환성
- 이전 코드는 새로운 코드가 기록한 데이터를 읽을 수 있어야 한다.
- 새 버전에 추가된 것을 무시할 수 있어야 하므로 적용이 어렵다.
데이터 부호화 형식
프로그램은 보통 두 가지 형태로 표현된 데이터를 사용해 동작한다.
메모리에 객체, 구조체, 리스트, 배열, 해시테이블, 트리 등으로 데이터가 유지된다.
이러한 데이터 구조는 CPU에서 효율적으로 접근하고 조작할 수 있게 최적화 된다.
데이터를 파일에 쓰거나 네트워크를 통해 전송하려면 스스로를 포함한 일련의 바이트열의 의 형태로 부호화해야 한다.
포인터는 다른 프로세스가 이해할 수 없으므르 이 일련의 바이트열은 보통 메모리에서 사용하는 데이터 구조와는 상당히 다르다.
인메모리 표현에서 바이트열로의 전환을 부호화(직렬화 또는 마샬링).
그 반대를 복호화 (파싱, 역직렬화, 언마샬링) 이라고 한다
Ex) Java - Serializable, Ruby - Marshal, Python - pickle 등등
JSON과 XML, 이진 변형
표준화된 부호화로서, JSON과 XML text 형식이며 인기가 많다.
JSON과 XML은 널리 알려져 있고 많은 곳에서 지원하지만 그만큼 호불호가 갈리고도 한다.
특히 XML의 경우 불필요하고 복잡하다고 비판받는다.
강력하지 않지만, csv도 인기 있는 언어 독립적인 형식이다.
수의 부호화에는 많은 애매함이 존재. 정수와 부동소수점 수를 구별 X, 정밀도 지정 X.
이 애매함은 큰 수를 다룰때 문제. 2^53보다 큰 정수를 다룰때 부정확해 질 수 있음.
JSON, XML은 유니코드 문자열은 잘 지원, 그러나 이진문자열을 지원하지 않음.
이러한 결점에도 JSON, XML, CSV는 사용하기 충분하고 인기 있음.
특히, 데이터 교환 형식에서 사용하기 매우 좋음.
Binary Encoding (이진 부호화)
json, xml과 비교해 더 적은 공간, 더 간결하고 더 빠른 파싱인데 data set이 적다면 별 의미가 없지만, terabyte 급이 된다면 이야기가 달라진다.
Json도 이진 형식과 비교하면 더 많은 공간을 사용한다.
이러한 관점이 json(message pack, BSON, BJSON, BISON, smile) 등으로 사용 가능한 이진 부호화 개발이 되었다.
다만, JSON만큼 사용되진 않는다.
예제4-1)
{ //1 byte
"userName" :"Martin", // 20 byte
"favoriteNumber" :1337, // 22 byte
"interests":["daydreaming", "hacking"] // 37 byte
} // 1 byte
json을 이진 부호화 한다고 해도 객체의 필드 이름을 포함해야 한다. (81바이트)
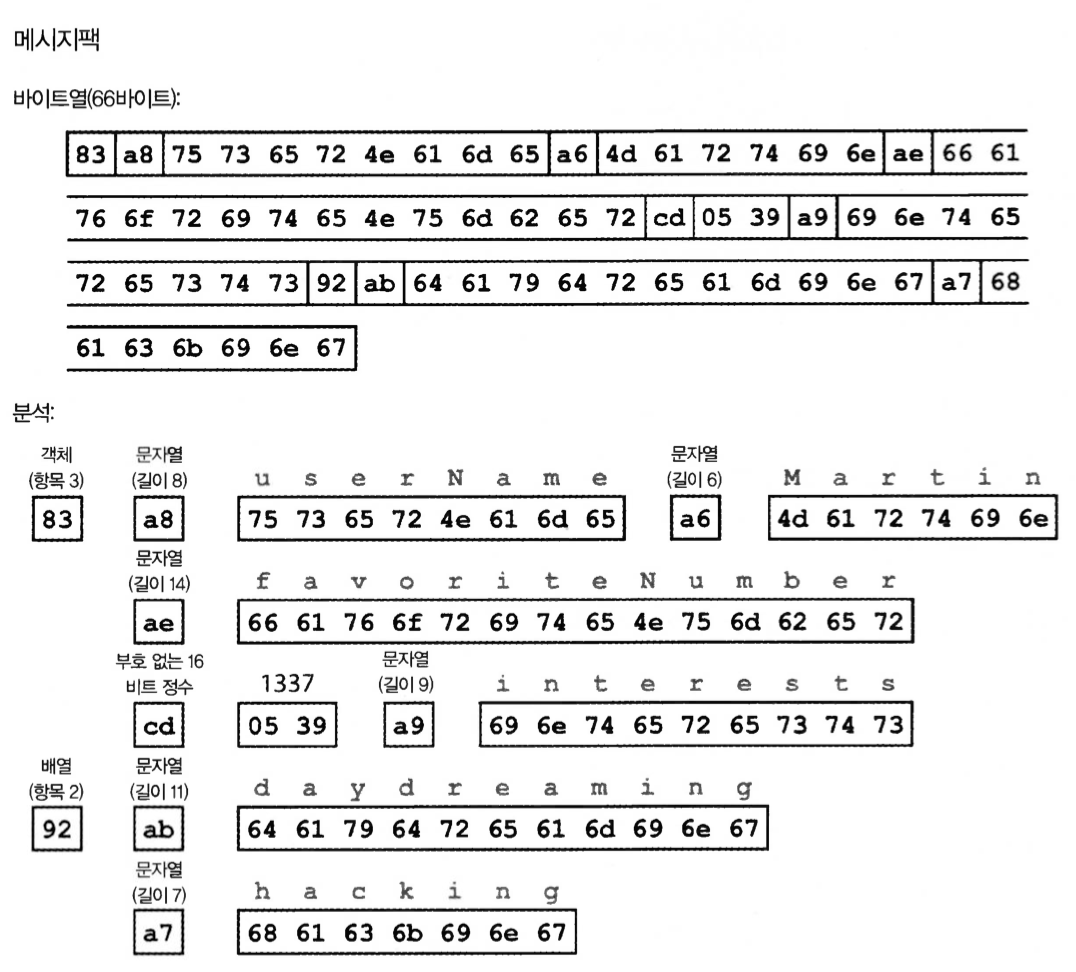
그림 4-1. 메시지팩으로 부호화한 예제 레코드(예제4-1)
Json 이진 부호화 66 바이트 (16진수)
참고)
- 0x83 = 0x80 (객체), 0x03 (필드) 3개의 필드를 가진 객체
- 0xa8 = 0xa0 (문자열), 0x08 (8바이트)
- cd = 16바이트 숫자, 16^2 * 5 = 1280. 16 * 3 = 48 . 9 = 1337
ASCII - 위키백과, 우리 모두의 백과사전 msgpack/spec.md at master | msgpack/msgpack | GitHub
스리프트와 프로토콜 버퍼
아파치 스리프트(Apache Thrift)와 프로토콜 버퍼(Protocol Buffers)는 같은 원리를 기반으로 한 이진 부호화 라이브러리
프로토콜 버퍼는 구글에서 개발, 스리프트는 페이스북에서 개발 => 현재 둘다 오픈소스
둘다 부호화할 데이터를 위한 스키마가 필요
# 스리프트 스키마
struct Person {
1:required string userName,
2:optional i64 favoriteNumber,
3:optional list<string> interests
}
# 프로토콜 스키마
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}
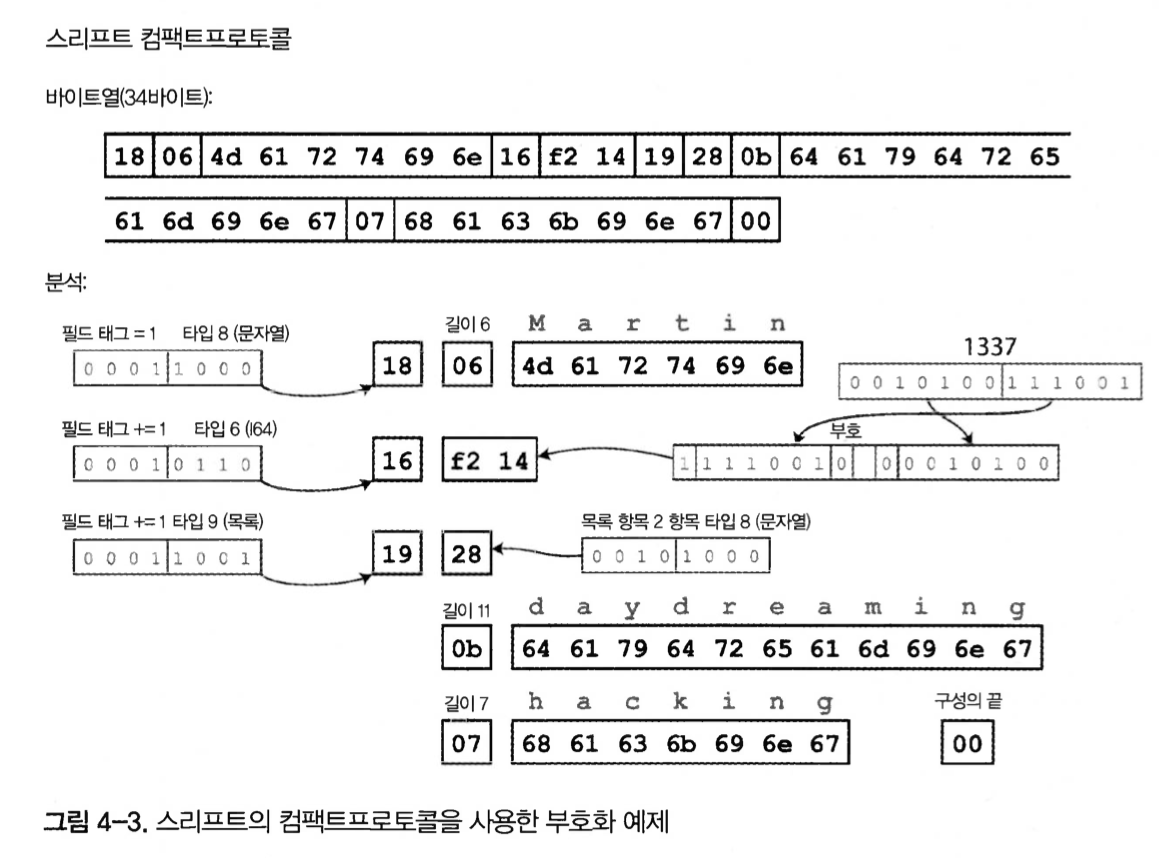
그림 4-3. 스리프트의 컴팩트 프로토콜을 사용한 부호화 예제
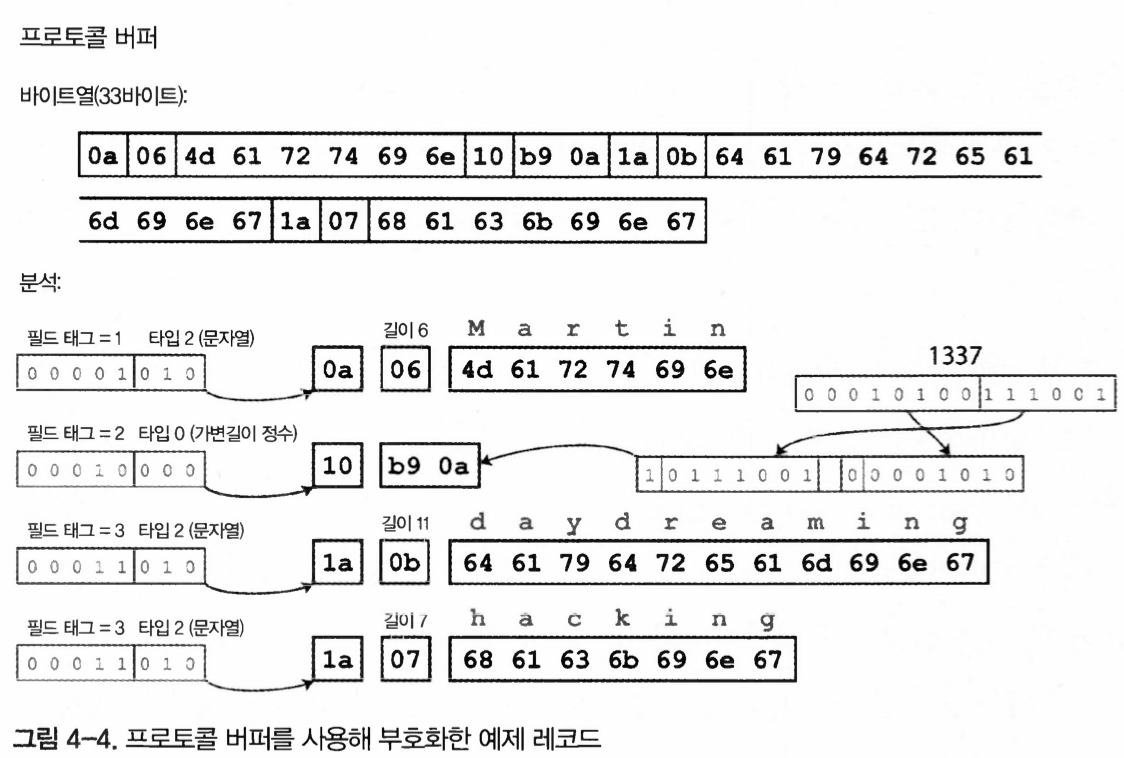
그림 4-4. 프로토콜 버퍼를 사용해 부호화한 예제 레코드
두 프로토콜 모두, 스키마를 이용해 바이트수가 급격히 줄었다.
가장 큰 차이점은 필드이름 대신 필드 태그(1,2,3)을 포함한다.
이 숫자는 스키마 정의에 나타난 숫자다.
필드태그와 스키마 발전
스키마는 필연적으로 시간이 지남에 따라 변한다. 이를 스키마 발전이라 한다.
어떻게 상위 호환성, 하위 호환성을 유지하면서 변경할까?
- 상위 호환성 (예전 코드는 현재 데이터를 읽을 수 있어야 함)
- 새로운 코드로 기록한 데이터를 읽으려 할 때 인식할 수 있는 tag 번호인지만 확인하여 인식이 안되면 자연스럽게 무시
- 하위 호환성 (지금 코드는 예전 코드로 생성한 데이터를 읽을 수 있어야 함)
- 최초 배포 후에는 required 로 field를 추가할 수 없음 (예전 코드로 생성한 데이터를 읽지 못함)
- optional field만 삭제 가능
아브로 (Apache Avro)
프로토콜 버퍼와 스리프트와 다르지만 이들과 대적할만한 또 하나의 이진 부호화 형식.
스리프트가 하둡의 사용 사례와 적합하지 않아 2009년 하둡에 하위 프로젝트로 시작.
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}
{
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favoriteNumber", "type": ["null","long"], "default": null},
{"name": "interests","type": {"type": "array","items": "string"}}
]
}
그림 4-5. 아브로를 이용한 부호화한 에제 레코드
32바이트로 길이가 가장 짧다
- 필드나 데이터타입을 식별하기 위한 정보가 없다
- 아브로를 사용해 parsing 하려면 schema를 먼저 읽고 각 필드의 데이터 타입을 기억해야 한다
쓰기 스키마와 읽기 스키마
- file, db, network를 통해 전송 목적으로 부호화하기 위해 사용
- application이 빌드하는 동안 스키마 생성
- 쓰기, 읽기의 스키마가 다를 수 있다. 또한 필드의 순서가 달라도 문제 없다
- 없는 필드를 만드면 이 필드를 무시후 기본값으로 채운다
아보로 스키마 발전 규칙
- 상위 호환
- 새로운 버젼의 쓰기 스키마와 예전 버전의 읽기 스키마를 가질 수 있음
- 필드 이름 변경 불가
- 하위 호환(예전 데이터를 지금도 읽을 수 있다)
- 새로운 버젼의 읽기 스키마와 예전 버젼의 쓰기 스키마를 가질 수 있다
- 필드 이름 변경을 추적할 수 있기 때문에 필드 이름 변경 가능
이러한 호환성을 유치하기 위해 default 가 있는 필드만 추가 삭제 가능
예전 스키마에 없는 값이 읽기 스키마에 있으면 기본값으로 대체
아브로는 스키마가 동적으로 변경될 가능성을 고려하여 설계됨
코드 생성과 동적 타입언어
- 스리프트와 프로토컬 버퍼는 코드 생성에 의존
- Java, C++, C# 같은 정적 타입 언어에서 유용
- 스키마가 변경되면 재컴파일 필요 avro는 이저한 관점에서 compile, interpreter 언어를 선택해 사용할 수 있다.
스키마의 장점
- 프로토컬버퍼, 스리프트 아브로는 스키마를 사용해 이진 부호화 형식을 기술한다.
- 이 스키마 언어는 xml, json 스키마 보다 훨씬 간단하며 더 자세한 유효성 검사 규칙을 지원한다.
- 부호화된 데이터는 필드 이름을 생략할 수 있어, data 크기가 json 에 비해 작을 수 있다.
- schema database 를 사용한다면 상위 호환, 하위 호환을 확인할 수 있다.
데이터플로 모드
하나의 프로세스에서 다른 프로세스로 데이터를 전달하는 방법
- DB를 통해
- 서비스 호출을 통해
- 비동기 메시지 전달을 통해
데이터베이스를 통한 데이터플로
- 데이터베이스에 기록하는 프로세스는 데이터를 부호화하고 읽는 프로세스는 복호화한다
- 단일프로세스로 DB에 접근
- DB에 저장하는 일은 미래의 자신에게 메시지를 보내는 일
- 하위 호환성이 분명히 필요
- 다양한 프로세스가 DB에 접근
- 흔한 방식의 application이나 서비스
- 순회식으로 배포를 한다면 새로운 버젼을 배포하는 몇몇 instance 는 예전 코드로 데이터를 저장하고 갱신중일 것
- 상위 호환성이 필요
- 부호화는 모르는 필드는 건들지 않지만 DB 관점에선 데이터가 유실될 수 있다
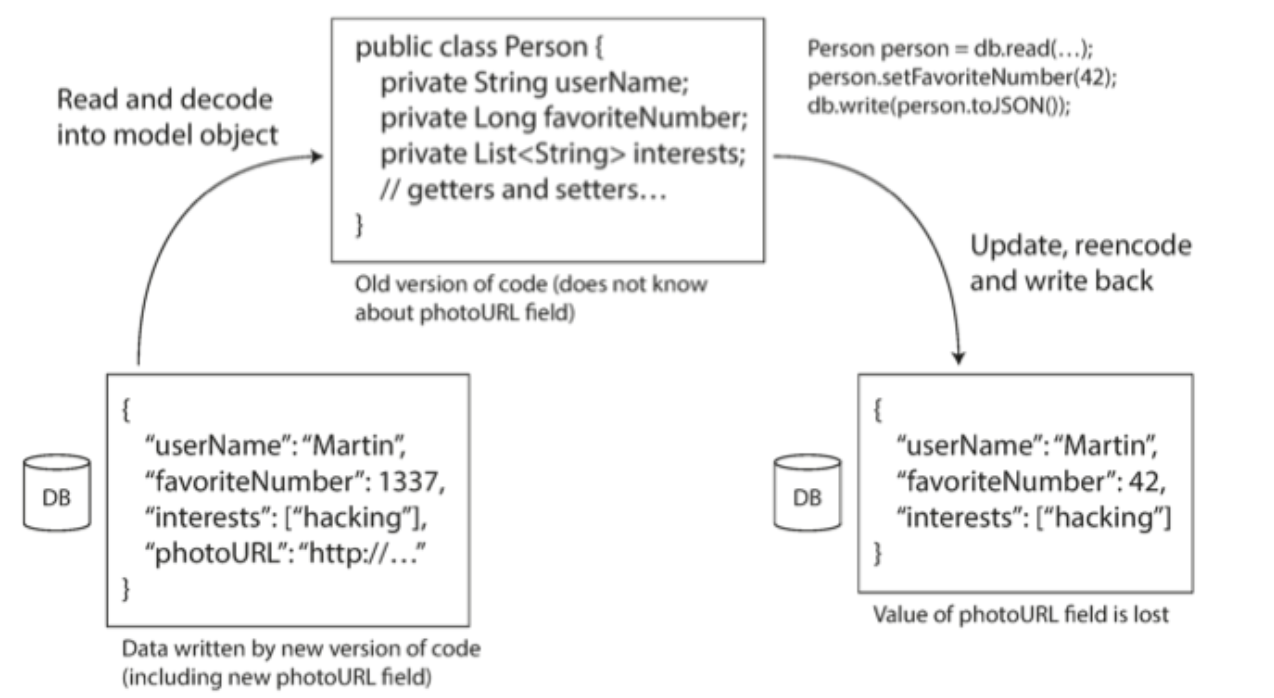
그림 4-7. 새로운 버전의 애플리케이션이 기록한 데이터를 예전 버전의 애플리케이션이 갱신한 경우 주의하지 않으면 데이터가 유실될 수 있다.
주의하지 않으면 이처럼 데이터 갱신시 새로운 필드의 데이터가 유실될 수 있다
다양한 시점에 기록된 다양한 값
- DB는 언제나 데이터를 갱신할 수 있다
- 이 데이터는 5년전 데이터일 수도 있고, 5ms 전에 기록됐을 수 있다
- DB에 별다른 기능을 실행하지 않는다면 원래 부호화 그대로 유지되어 있을 것이다
- 데이터를 새로운 스키마를 통해 다시 기록 할수 있지만 마이그레이션하는 작업은 큰 비용이 든다
보관 저장소
- 백업 목적이나 데이터 웨어하우스로 적재하기 위해 데이터베이스의 스냅숏을 수시로 만든다.
- 이 경우 최신 스키마를 이용해 부호화한다.
서비스를 통한 데이터플로: REST와 RPC
- 네트워크를 통해 통신해야하는 프로세스가 있을때 해당 통신을 배치하는 몇가지 방법이 있다
- 가장 일반적인 방법으로는 클라이언트와 서버의 두 역할로 배치하는 것이다
- 서버가 네트워크를 통해 API를 공개하고 클라이언트는 이 API로 요청을 만들어 서버에 연결한다
- 서버가 공개한 API를 서비스라 한다
웹은 다음과 같은 방식으로 동작한다
- 클라이언트는 웹서버로 요청을 보낸다
- GET 요청을 보내고 HTML, CSS, JS, Image 등을 받는다
- 서버는 데이터를 전송하기 위해서 POST 요청을 보낸다
- 웹에서 웹 브라우저만 유일한 client는 아니다.
- 모바일 디바이스, 데스크톱 기본앱도 서버에 네트워크를 요청할 수 있다
- 서버 자체가 다른 서비스의 클라이언트일 수도 있다
- 예를 들어 하나의 서비스가 다른 서비스의 일부 기능이나 데이터가 필요하다면 해당 서비스에 요청을 보낸다
- 이런 application 개발 방식을 전통적으로 서비스 지향 설계 (SOA)라 불렀다
- 최근엔 이런 더욱 개선해 마이크로서비스 설계란 이름으로 재탄생했다
서비스와 Database는 여러가지 측면에서 유사하다. 단, 차이는 service 는 비즈니스 로직에 기반하여 입출력을 제한하고, 정해진 입출력만 허용해 API를 공개한다는 것이다.
MSA, SOA의 목표는 서비스를 배포와 변경에 독립적으로 만들어 application의 유지보수를 더 쉽게 만드는데 있다.
즉 변경이 잦을것을 대응하기 위한 것이며 새로운 버젼 출시가 빠르기 때문에 API간 호환이 필요하다. 이점이 이번 장의 핵심 내용이다.
웹서비스
- 서비스와 통신하기 위한 기본 프로토콜로 HTTP를 사용할 때 이를 웹 서비스라고 한다
- 웹서비스에는 대중적인 두가지 방식 REST와 SOAP이 있다
REST
- HTTP를 원칙을 토대로 설계한 원칙
- 간단한 데이터 타입을 강조
- URL을 사용해 Resource를 식별하고 캐시 제어, 인증, 콘텐츠 유형 협상
- SOAP이 비해 인기있다.
SOAP
- 네트워크 API 요청을 위한 XML 기반 프로토콜
- HTTP 상에서 일반적으로 사용하지만, HTTP와 독립적이며 HTTP 기능을 사용하지 않는다.
- 그대신 다양한 기능을 추가한 광범휘하고 복잡한 여러 관련 표준을 제공
- 사람이 읽을 수 없도록 설계되어 도구나 IDE에 크게 의존한다.
- 대부분은 RESTful API 를 통한 간단한 접근 방식을 선호한다.
원격 프로시저 호출(RPC) 문제
- 웹 서비스는 network 상에서 API를 호출하는 여러 기술중 가장 최신의 형상일 뿐이다
- 웹서비스는 1970년대부터 사용한 원격 프로시저 호출 (RPC)의 아이디어를 기반으로 한다
- RPC 모델은 원격 network 서비스 요청을 같은 process 안에서 특정 method를 호출하는것 처럼 사용 가능하게 해준다
- RPC가 처음에는 편리한 것 같지만 RPC 접근 방식은 근본적으로 결함이 있다
- 로컬함수 호출은 결과를 반환하거나 예외를 반환하지 않을 수 있다
- 실패한 네트워크 요청을 다시 시도할 때 요청이 실제로는 처리되고 응답만 유실될 수 있다
- 로컬함수를 호출할 때마다 보통 거의 같은 실행 시간이 소요된다
- 로컬 함수를 호출하는 경우 참조(포인터)를 로컬 메모리의 객체에 효율적으로 전달할 수 있다
- 클라이언트 서비스는 다른 프로그래밍 언어로 구현할 수 있다
RPC의 현재 방향 이러한 문제에도 불구하고 RPC는 사라지지 않았으며, 지금까지 언급한 이진 부호화 위에 RPC 프레임워크가 개발되었다.
- thrift, avro 는 RPC 지원 기능을 내장하고 있다
- gRPC는 protocol buffer를 이용해 RPC를 구현했다
- Finagle은 thrift를 사용하고 Rest.li는 HTTP 위에서 json을 사용한다
데이터 부호화와 RPC의 발전
- 발전성이 있으려면, RPC client와 서버를 독립적으로 변경하고 배포할 수 있어야 한다
- 데이터베이스를 통한 데이터플로에 비해 발전성은 가정을 단순화 할 수 있다
- 모든 서버를 먼저 갱신하고 나서 모든 클라이언트를 갱신해도 문제가 없다고 가정한다
- 그러면 요청은 하위 호환성만 필요하고 응답은 상위 호환성만 필요하다
API 버젼 관리가 반드시 어떤 방식으로 동작해야 한다는 합의는 없으나, 일반적으로 HTTP Aceept 헤더에 버전 번호를 사용하는 방식이 일반적이다
메시지 전달 데이터플로
- 메시지 전달 데이터플로는 RPC와 데이터베이스간 비동기 메시지 전달 시스템이다
- 클라이언트 요청을 낮은 지연 시간으로 다른 프로세스에 전달한다는 점에서 RPC와 비슷
- 메세지를 직접 네트워크 연결로 전송하지 않는다
- 임시로 메시지를 저장하는 메세지 브로커를 이용
- 또는 메시지 지향 미들웨어라는 중간 단계를 거쳐 전송한다
Message broker를 사용했을때 장점
- 수신자가 사용 불가능하거나 과부하 상태라면 메시지 브로커가 버퍼처럼 동작할 수 있다.
- 죽었던 프로세스에 메세지를 다시 전달할 수 있기 때문에 메시지 유실을 방지할 수 있다.
- 송신자가 수신자의 IP 주소나 포트 번호를 알 필요가 없다.
- 하나의 메세지를 여러 수신자로 전송할 수 있다.
- 논리적으로 송신자는 수신자와 분리된다할 뿐이고 누가 소비하는지 상관하지 않는다.
메시지 전달 통신은 일반적으로 단방향이라는 점이 RPC와 다르다. 즉, 송신 프로세스는 대게 메시지에 대한 응답을 기대하지 않는다.
메시지 브로커
- 최근엔 래빗MQ, 액티브MQ, 호닛Q, 아파치카프카 같은 오픈소스 구현이 대중화 됐다
- 세부전달 전달 시맨틱은 구현과 설정에 따라 다양하다
- 하지만, 일반적인 메시지브로커는 다음과 같이 사용한다
- 메시지이름이 지정된 큐나 토픽으로 전송
- 브로커는 해당 큐나 토픽 의 하나 이상의 컨슈머 또는 구독자에게 메세지를 전달
- 동일한 토픽에 여러 생산자와 소비자가 있을 수 있다
- 토픽은 단방향 데이터플로만 제공
분산 액터 프레임워크
- 액터 모델은 단일 프로세스안에서 동시성을 위한 프로그래밍 모델이다
- 스레드 경쟁 조건, 잠금, 교착상태를 직접 처리하는 대신 로직이 액터에 캡슐화 된다
- 각 액터는 하나의 클라이언트나 엔티티를 나타낸다
- 액터는 로컬 상태를 가질수 있고 비동기 메시지의 송수신으로 다른 액터와 통신한다
- 액터는 메세지 전달을 보장하지 않는다
분산 액터 프레임워크는 노드간 application 확장에 사용하는데 송신자, 수신자가 같은 노드이건 아니건 관계없이 동일한 메세지 전달 구조를 사용한다. 만약 다른 노드이면 부호화되고 network를 통해 전송된다.
액터 모델은 메세지가 유실된다는 가정을 가지기 때문에 위치 투명성은 RPC 보다 actor 모델에 더 잘 동작한다(로컬과 원격 통신간 불일치를 줄여준다)
정리
다양한 데이터 부호화 형식과 호환성 속성
- 프로그래밍 언어에 특화된 부호화는 단일 프로그래밍 언어로 제한되며 상위 호환성과 하위 호환성을 제공하지 못하는 경우가 있다
- JSON, XML, CSV 같은 텍스트 형식은 널리 사용된다
- 이들간 호환성은 데이터타입을 사용하는 방법에 달려 있어 스키마가 있으면 유용할 수 있으나 반대로 불편할 수 있다
- 스리프트, 프로토콜, 아브로 같은 이진 스키마 기반은 짧은 길이로 부호화 되어 효율적
- 단, 이진 부호화는 사람이 읽을 수 있도록 하기위해 복호화 과정이 필요하다
데이터 부호화에 대한 시나리오 data flow mode
- 데이터베이스에 기록하는 프로세스가 부호화하고 데이터베이스에 읽는 프로세스사 복호화하는 데이터베이스
- 클라이언트가 요청을 부호화하고 서버는 요청을 복호화하고 응답을 부호화하고 최종적으로 응답을 복호화하는 RPC와 REST API
- 송신자가 부호화하고 수신자가 복호화하는 메시지를 서로 전송해서 노드간 통신하는 비동기 메시지전달 (메시지브로커나 액터를 이용)