스트림 처리란? OSS 엔진 소개
스트림 처리란?
예를 들어, 벨트 컨베이어를 흐르는 티셔츠에 대해 센서를 사용하여 색상별로 분리하여 골판지에 포장하는 경우를 생각해 보자.
이 경우 “스트리밍 데이터"와 “스트림 처리"는 각각 다음과 같다.
- 스트리밍 데이터: 센서가 전송하는 티셔츠 이미지
- 스트림 처리 : 센서에서 수신한 티셔츠의 이미지를 바탕으로 AI가 실시간으로 색상을 결정
스트림 처리 VS 배치 처리
여기서는 스트림 처리와 배치 처리를 비교하여 스트림 처리의 특성을 이해한다.
스트림 처리와 배치 처리의 차이는 시간축의 차이이다.
| 스트림 처리 | 배치 처리 | |
|---|---|---|
| 목적 | 실시간(realtime) 중시 | 처리량(throughput) 중시 |
| 처리할 타이밍 | 스트리밍 데이터가 발생했을 때 | 하드웨어 리소스가 남을 때 |
| 처리에 걸리는 시간 | 몇 밀리초 ~ 몇 초 | 몇 분 ~ 몇 시간 |
| 유즈 케이스 (사용 사례) |
신용 카드 사기 탐지 게임의 실시간 세계 순위 IoT 장치 데이터 분석 |
야간 배치 점포의 월별 처리 |
유스 케이스를 보면 알 수 있듯이, 스트림 처리는 시간이 지남에 따라 무한히 발생하는 데이터를 실시간으로 처리하여 하는 경우에 사용된다.
예를 들어, 신용 카드의 부정 이용은 1초라도 빨리 인지를 하여 사용을 중지해야 한다. 다음달까지 처리한다 등과 같이 늦어서는 안된다.
스트리밍 데이터란?
또한, 스트리밍 데이터는 “이벤트 스트림"이나 “데이터 스트림” 이라고도 불린다.
스트리밍 데이터는 무한이라고 하는 것 외에, 아래 3개의 특성을 가진다.
- 순서가 지정
- 불변(immutable) 데이터 레코드
- 재생 가능 (※ 있으면 하는 특징)
순서가 지정
이벤트(스트리밍 데이터의 각 레코드)에는 순서가 지정된다.
예를 들면, 이벤트 1 “급여 200 만원 송금”, 이벤트 2 “50만원 인출"에는 순서가 있다. 잔액 0원 계좌의 경우, 이벤트 2가 먼저 처리되게 되면 잔고 부족이 발생해 버린다.
불변(immutable) 데이터 레코드
이벤트는 한번 발생하면 삭제, 변경할 수 없다.
예를 들어, 이벤트 “50만원 인출"을 나중에 삭제하거나 변경할 수 없다. 이 이벤트를 취소하려면, 새로운 이벤트 “5만원 입금"을 실행한다.
재생 가능
순서가 지정되어 있고, 변동 가능한 데이터 레코드로 인해 스트리밍 데이터를 재현할 수 있다.
예를 들어, 다음 이벤트 목록에서 현재 잔액을 찾는 것은 물론 어느 시점에서 잔액을 찾는 것도 가능하다.
- 이벤트 1 : 잔고 0원으로 계좌 개설
- 이벤트 2 : 50만원 입금
- 이벤트 3 : 100만원 입금
- 이벤트 4 : 50만원 인출
- 이벤트 5 : 50만원 입금
- 이벤트 6 : 100만원 인출
또한, 이벤트 리스트로부터 과거가 있는 상태의 데이터를 재현하는 것을 **머티리얼라이즈(Materialise, 구체화되다)**라고 한다. 이벤트 4 종료 시점에서의 “잔고 데이터"를 구체화하면 “100만원"이 된다.
스트림 처리의 시간 개념
스트림 처리에서는 시간을 기반으로 스트리밍 데이터를 처리할 수 있으므로 정확한 시간 개념을 정의하는 것이 중요하다. 스트림 처리에서는 아래 3개의 시간의 개념을 이용한다.
- 이벤트 시간(Event Time)
- 수집 시간(Ingest Time)
- 처리 시간(Processing Time)
이벤트 시간(Event Time)
이벤트 시간은 스트리밍 데이터를 분석하는데 사용된다.
- 웹 사이트에 액세스하는 피크 시간
- 매시간 매출이 증가하는 상품의 종류
수집 시간(Ingest Time)
스트림 처리에서는 실시간으로 처리를 하기 때문에, 통상적으로 “이벤트 시간"과 “수집 시간"은 거의 같다.
네트워크 장애 등에 의해, 데이터의 도착에 지연이 발생했을 경우에 “이벤트 시간"과 “수집 시간"은 격차가 생긴다.
처리 시간(Processing Time)
“처리 시간"과 “수집 시간"에 큰 격차가 있는 경우에는 어플리케이션측에서 스트림 처리가 사이에 맞지 않을 가능성이 있다.
타임 윈도우(Time Window)
스트림 처리에서는 스트리밍 데이터에 대해서 시간 기간으로 윈도우를 조작하는 것이 가능하다.
타임 윈도우에서는 시간을 기준으로 윈도우 사이즈를 결정한다. (10초마다 쌓인 레코드를 처리한다 등)
타임 윈도우의 타입에는 윈도우의 이동 빈도(전진 간격)에 의해 주로 이하의 3가지 종류가 있다.
| 윈도우 이동 빈도(전진 간격) | 처리 중복 | |
|---|---|---|
| 텀블링 윈도우(Tumbling window) | 윈도우 사이트와 동일하다. | 하지 않는다. |
| 호핑 윈도우(Hopping window) | 윈도우 사이트보다 작다. | 한다 |
| 슬라이딩 윈도우(Sliding window) | 윈도우내에 있는 이벤트가 변화할 때마다 매번 | 할 수도 있다. |
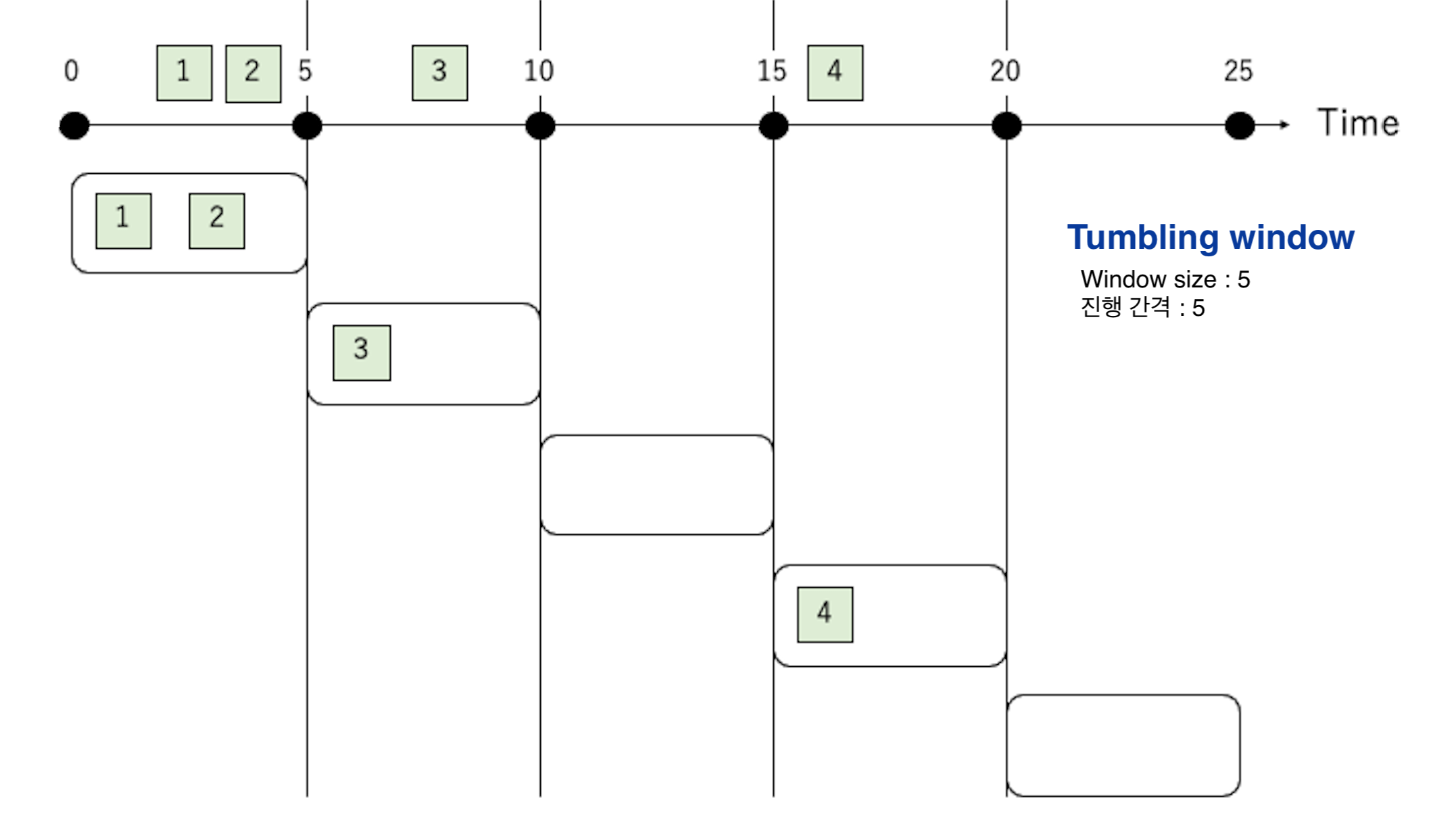
텀블링 윈도우(Tumbling window)
“이동 빈도"와 “윈도우 사이즈"가 같은 윈도우 타입이다.
이벤트에 대한 처리가 중복되지 않는 특징이 있다.
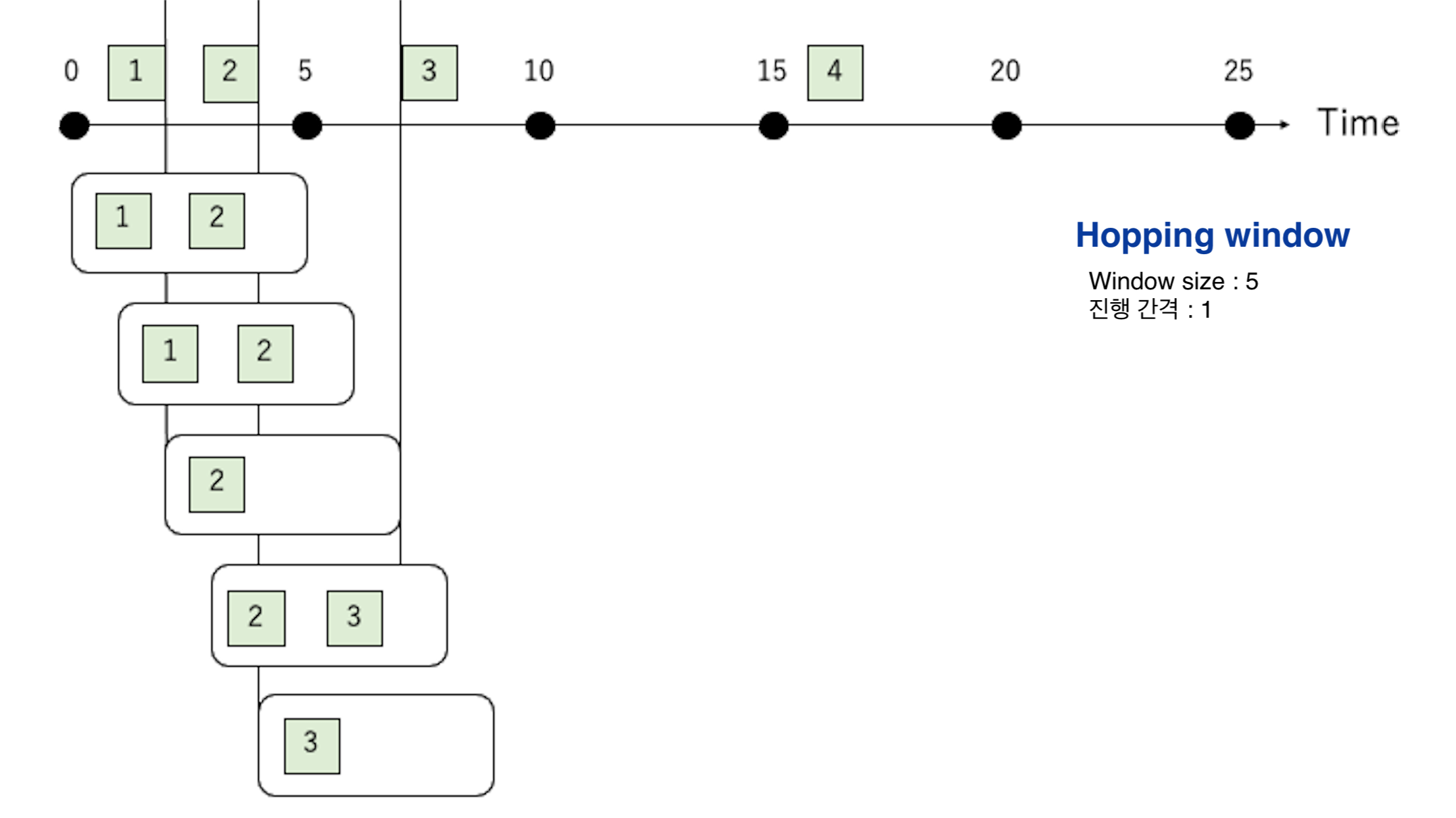
호핑 윈도우(Hopping window)
“이동 빈도” 보다 “윈도우 사이즈"가 큰 윈도우 타입이다.
이벤트에 대한 처리가 중복되는 특징이 있다.
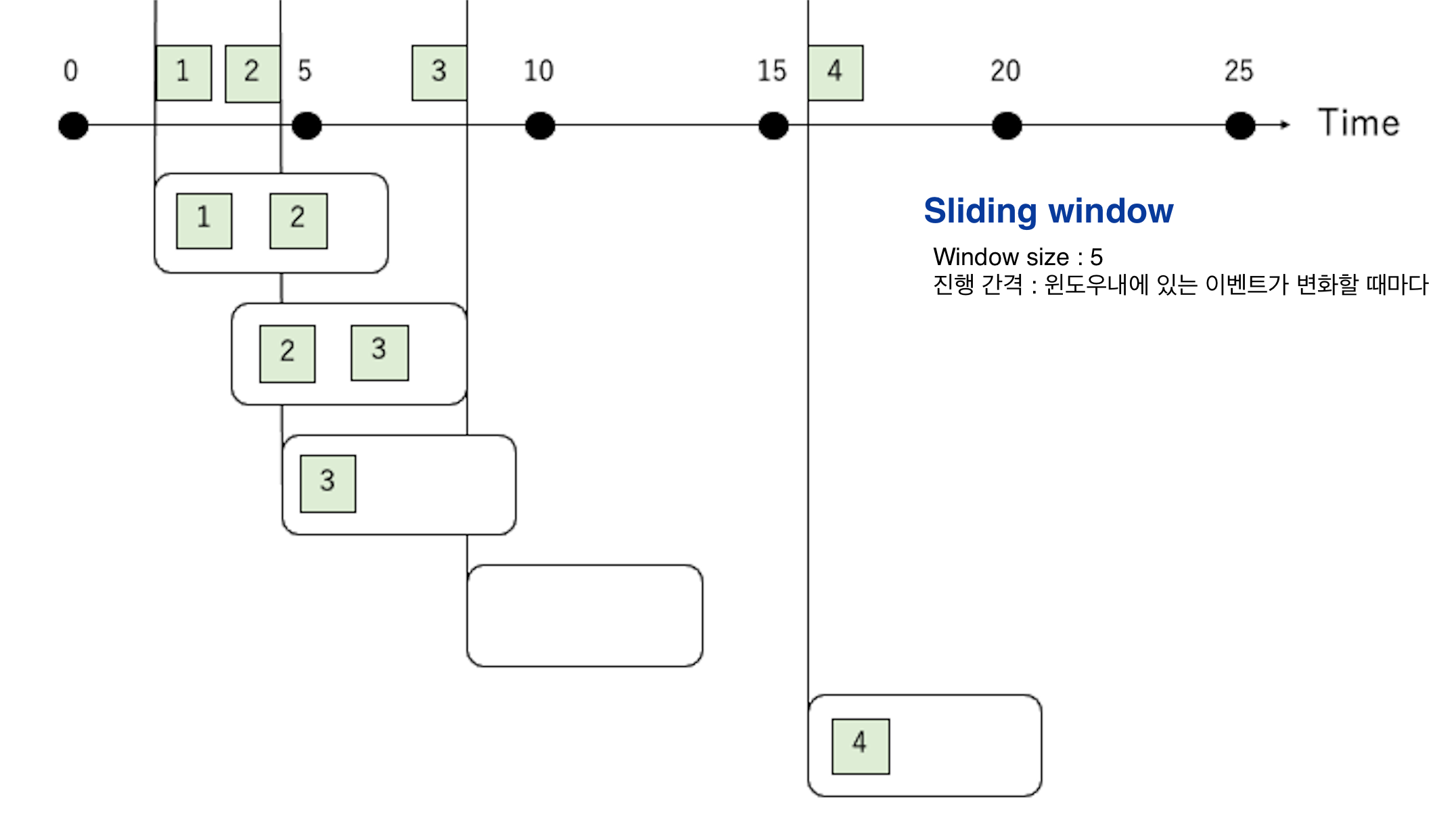
슬라이딩 윈도우(Sliding window)
“이동 빈호"가 “윈도우내에 있는 이벤트가 변화할 때"가 같은 윈도우 타입이다.
윈도우내에 있는 이벤트가 변경되지 않을 때는 아무 작업도 수행하지 않다. (SQL 쿼리의 경우 결과를 출력하지 않는다.)
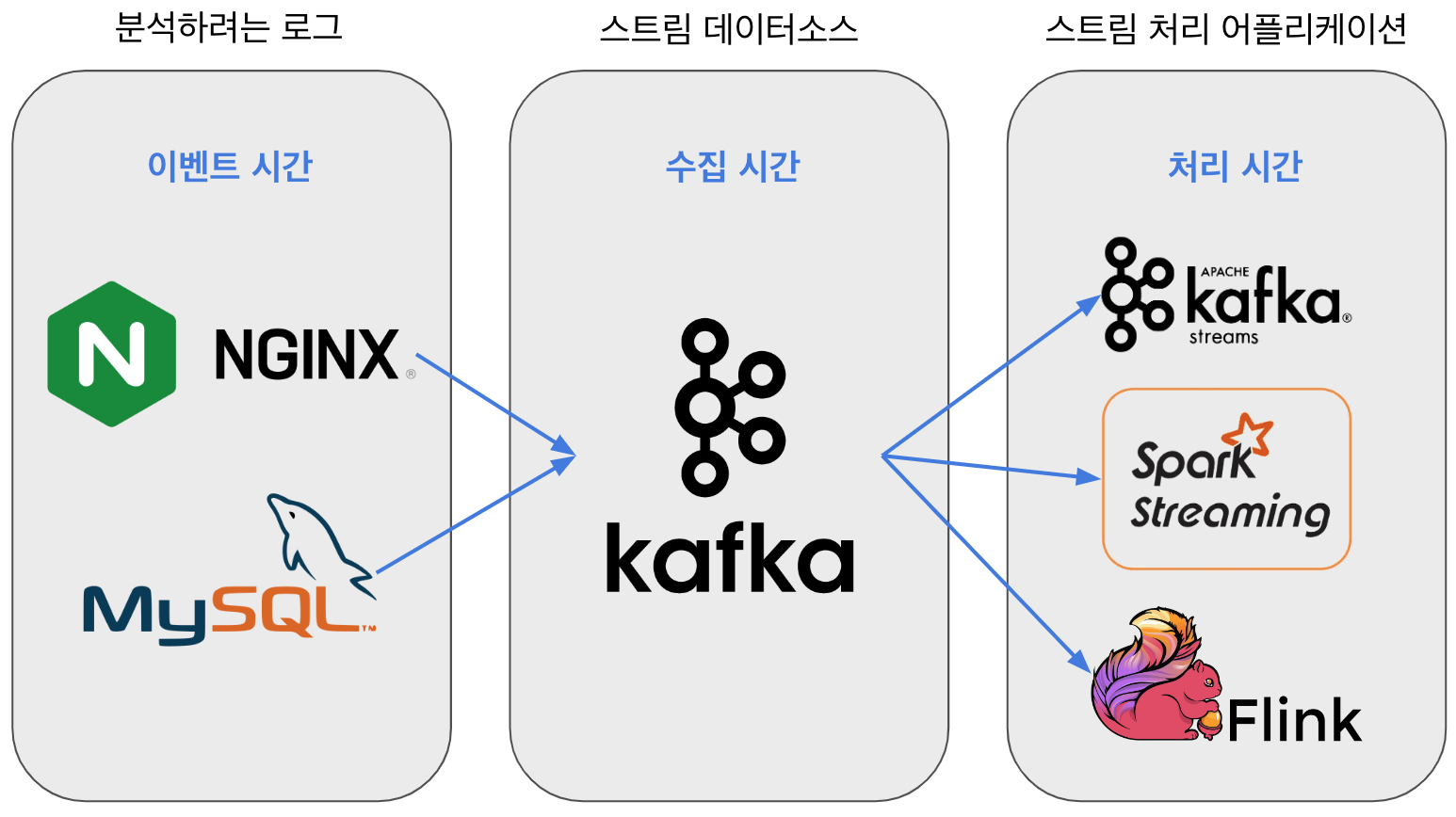
스트림 처리하는 OSS 및 서비스
스트림 처리는 아래의 2가지를 이용하여 할 수 있다.
- 분산 스트리밍 데이터 소스(이벤트를 큐잉하는 데이터 소스)
- 분산 스트림 처리 어플리케이션(큐의 이벤트에 스트림 처리를 실시)
분산 스트리밍 데이터 소스
분산 스트리밍 데이터 소스는 주로 다음 Pub/Sub 메시징 대기열을 사용한다.
- Apache Kafka
- Amazon Kinesis Data Streams
분산 스트림 처리 애플리케이션에서 사용하는 엔진
분산 스트림 처리 어플리케이션에서는 주로 아래의 분산 처리 엔진을 이용한다.
- Kafka Streams (Apache Kafka의 Streams API)
- Kinesis Data Analytics
- Apache Flink
- Apache Spark Streaming
- 아파치 스톰
- Apache Samza
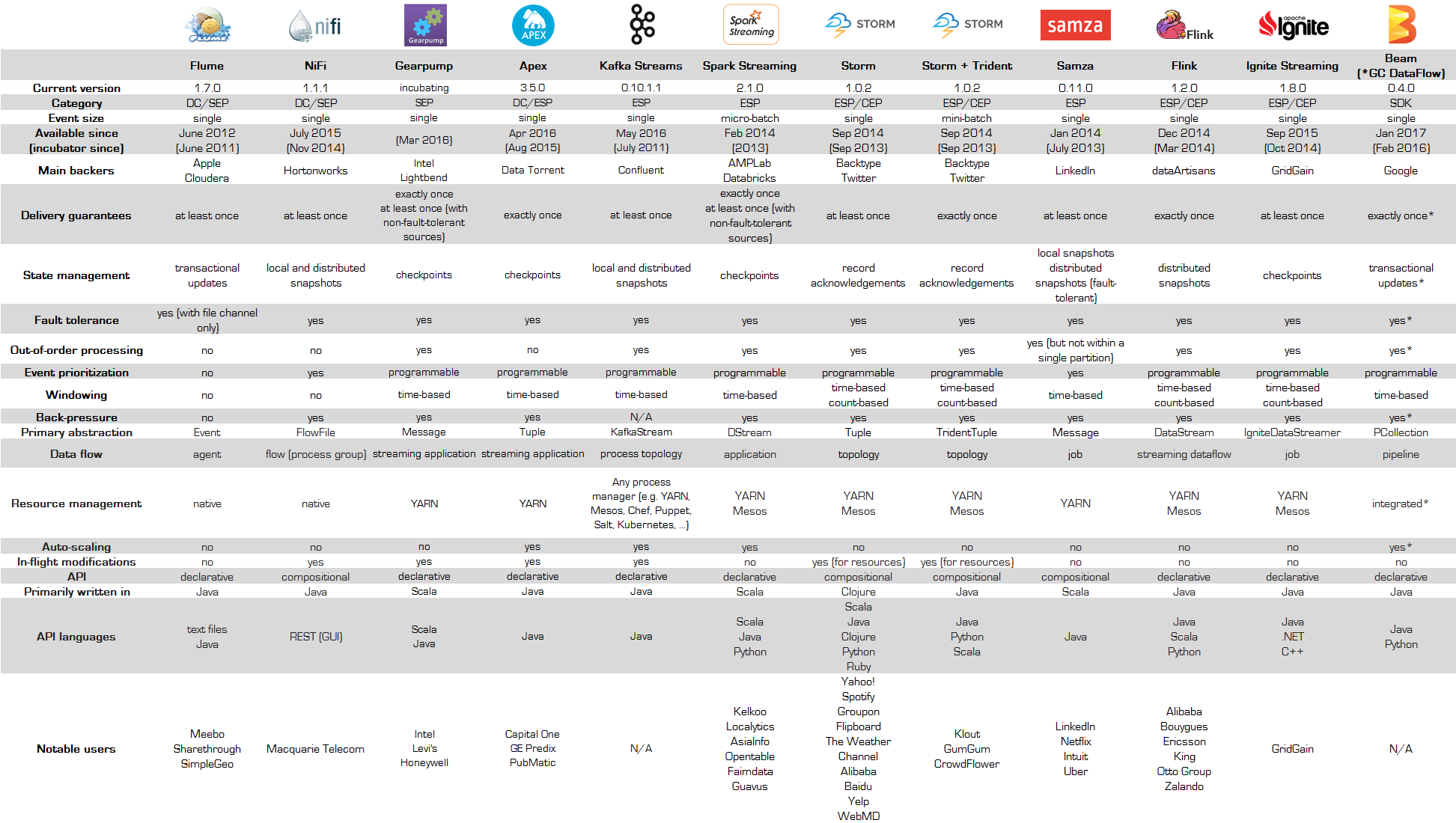
https://databaseline.tech/an-overview-of-apache-streaming-technologies/
기업의 스트림 처리 사례
스트림 처리(Apache Kafka + Kafka Streams)를 기업에서 사용한 사례는 아래와 같다.
- LINE 회사: Multi-Tenancy Kafka cluster for LINE services with 250 billion daily messages
- Cerner 회사: 주요 의료 IT 기업 Cerner사의 Kafka 활용 사례
- Bosch 회사: Tools Streams IoT Data with Confluent Cloud