Kafka 상세 개념 | 원래 Kafka란?
원래의 Kafka란?
Kafka는 이벤트 스트리밍 플랫폼이라는 미들웨어이다. 원래는 스트림 버퍼라고 불렸을 것이다.
공식 문서에는 다음과 같이 쓰여져 있다.
Kafka combines three key capabilities so you can implement your use cases for event streaming end-to-end with a single battle-tested solution:
- To publish (write) and subscribe to (read) streams of events, including continuous import/export of your data from other systems.
- To store streams of events durably and reliably for as long as you want.
- To process streams of events as they occur or retrospectively.
And all this functionality is provided in a distributed, highly scalable, elastic, fault-tolerant, and secure manner.
즉, 이벤트 스트림을 쓰거나 읽어들일 수 있고, 지속적으로 다른 시스템으로부터 import 하거나 export를 할 수 있다. 이는 일정 기간(또는 무기한) 유지할 수 있어, 이벤트 발생했을 때 바로 처리할 뿐만 아니라 거슬러 올라가서 이전의 데이터를 처리할 수도 있는 플랫폼이라는 것이다. 또한, 분산 처리 가능하고 확장(Scaleable)이 가능하다고 한다.
플랫폼의 구성 요소는 다음과 같다.
- Kafka Broker 미들웨어 본체
- Kafka Client 미들웨어와 통신하기 위한 클라이언트 라이브러리
- 상기 클라이언트에 의해 구현된 관리 명령 모음
- Kafka Streams and Kafka Connect 애플리케이션 개발을 위한 프레임워크
이벤트 스트림이란?
끊임없는 지속적인 데이터 흐름을 말한다.
시스템적으로는 데이터베이스나 모바일 디바이스 등에 의해 발생한 데이터의 움직임을 실시간으로 캡처한 데이터의 흐름이라고 할 수 있다. 각각의 데이터의 발생이나 변화를 이벤트라고 부르고, 이것이 끊임없는 연속되어 이어지는 것을 이벤트 스트림이라고 부른다. 이 이벤트 스트림에 대해 고속으로 처리를 할 수 있으며, 시스템은 사용자에게 즉시 최신의 결과를 전달할 수 있게 된다.
이벤트 스트림에는 끊임없는 존재하지 않는 데에 그 목적상 리얼타임에 가까운 간격으로 처리하는 것이 요구되기 때문에, 기본적으로는 1건 단위로 처리를 실시하게 된다. 집계 등의 여러 레코드에 걸친 처리에 대해서는 개발자 스스로 필요한 데이터의 범위를 정의해 정보를 축적해 두는 스토리지를 별도 준비할 필요가 있다.
Kafka의 에코시스템에는 이러한 스트림 처리로 현실적인 유스케이스를 실현하는데 필요한 라이브러리도 준비되어 있다.
Kafka에서는 여러 이벤트 스트림을 처리할 수 있으며 이를 토픽(topic)이라고 한다. 토픽은 이름을 붙여 관리할 수 있도록 한 것이 이벤트 스트림이다.
토픽과 파티션
각 토픽은 하나 이상의 파티션으로 분할된다. 또한 토픽에는 replication factor가 설정되어, 각 파티션의 복제본이 얼마나 존재하는지 설정할 수 있다. replication factor가 3이면 한 파티션 의 데이터 복제가 클러스터 내부에 3개 존재한다는 것을 뜻한다.
하나의 파티션에 있는 복제본은 하나의 노드에 의해 유지된다.
예를 들어, “TopicaA"의 파티션 수가 8이고, replication factor가 3이면 클러스터에 속한 각 노드에 총 24개의 파티션 의 데이터가 분산되어 배치된다.
kafkacat(kcat) 명령의 출력은 다음과 같다. 노드 수는 5대.
topic "TopicA" with 8 partitions:
partition 0, leader 5, replicas: 5,3,1, isrs: 1,5,3
partition 1, leader 3, replicas: 3,4,2, isrs: 4,2,3
partition 2, leader 1, replicas: 1,4,2, isrs: 1,4,2
partition 3, leader 4, replicas: 4,2,5, isrs: 4,2,5
partition 4, leader 2, replicas: 2,5,3, isrs: 2,5,3
partition 5, leader 5, replicas: 5,2,3, isrs: 2,5,3
partition 6, leader 3, replicas: 3,5,1, isrs: 1,5,3
partition 7, leader 1, replicas: 1,5,3, isrs: 1,5,3
주제에 보관할 데이터의 한 행 한 행을 레코드라고 하며 레코드는 키-값 쌍으로 구성된다. Kafka의 Broker에게는 키와 값은 단순한 바이트 열이며, 클라이언트가 어떤 형식의 데이터인지를 구별한다. 예를 들어, JSON 직렬화 된 데이터인 경우나 Avro나 ProtocolBuffer에 의해 바이너리 직렬화 된 데이터인 경우, 단지 캐릭터 라인인 경우, 바이트열을 그대로 수치로서 이용하는 경우 등을 직렬화 방식에 의존한다.
왜 카프카가 필요한가?
Kafka는 매우 응용 범위가 넓기 때문에 한마디로 설명하기가 어렵지만, 다음과 같이 활용할 수 있다.
- 시스템 느슨한 결합 및 확장성 향상을 위한 메시지 브로커
- 웹 시스템의 행위 추적
- 시스템 부하 등을 모니터링하기 위한 메트릭 기록
- 로그 집계
- 이벤트 소싱
카프카는 큐가 아니다
Kafka는 큐와 같이 동작할수 있고, 분산 큐라고도 하지만 정확하게는 큐가 아니다.
Kafka는 이벤트 스트림을 일정 기간 동안 유지하고 있으며, Consumer가 이를 처리해도 큐와 다르게 유지하는 데이터는 변경되지 않는다. 큐의 경우에는 Consumer가 데이터를 처리하면 해당 데이터가 큐에서 삭제되고 다른 작업자가 더 이상 사용할 수 없게 된다. 그리고, 기본적으로 선두의 데이터가 사라지지 않는 한 다음의 레코드는 처리되지 않는다. 예를 들어 AWS SQS는 그렇게 작동한다. (visibility timeout으로 어느 정도 순서는 제어할 수 있다) AWS 에서는 Kinesis(실시간 데이터 분석 처리 시스템)가 비교적 Kafka에 가까운 서비스이다. 현재는 Amazon Managed Streaming for Apache Kafka(MSK)도 제공되고 있다.
큐가 아닌 것에 의한 이점
토픽 공유
데이터가 계속 유지된다는 것은 하나의 토픽을 여러 시스템에서 공유할 수 있다는 것을 의미한다. 즉, 데이터 소스는 Kafka에 데이터를 전송하는 것만으로, 여러 마이크로서비스를 동작하는 것이 가능하다. 그 이전에 어떤 서비스가 있는지 알 필요는 없다. 각 서비스 측은 자신이 어느 토픽을 이용하는지만 알고 있으면 되고, 거기에서 데이터를 꺼내 자신의 처리만 하기만 하면 되기 때문에, 데이터의 발생지에 대해 알 필요는 없어진다. 만약 데이터를 이용하고 싶은 서비스가 늘어난다고 해도, 데이터의 발생지에서 목적지를 추가할 필요는 없다. Kafka의 본체가 되는 미들웨어를 메시지 브로커라고 부르는데, 이와 같이 메시지를 중개해 서비스간을 느슨한 결합으로 유지하는 역할을 할 수 있다.
내구성
Consumer가 데이터를 처리해도 데이터가 변경되지 않는다는 것은 Consumer가 처리 중에 오류가 발생하여 처리 노드별로 다운되었다고 해도 데이터가 손실되지 않는다는 것을 의미한다. 따라서 Consumer에서 오류가 발생해도 다시 큐를 할 필요가 없으며, 다른 노드에서 동일한 오프셋에서 처리를 계속하면, 데이터를 잃지 않고 처리를 되돌릴 수 있다. 사이드킥(sidekiq)와 같이 Redis를 처리 대기열로 사용하면 처리중인 작업자(worker)가 오류 처리를 제대로 수행하지 않으면 데이터가 손실 될 위험이 있다. 만약 OOM(Out Of Memory) 등에 의해 프로세스가 갑자기 죽은 경우에는 복구가 불가능하다. Kafka에서는 그런 걱정을 할 필요가 없다.
한편, exactly once 모드를 이용하지 않는 한은 리트라이(retry)에 의해 이중 처리될 가능성이 있기 때문에, 불균일성에 관해서는 별도 주의가 필요하다.
과거 데이터 이용 가능
Kafka는 일정 기간(기본적으로 7일간)의 데이터를 유지하고 있는 것 외에도 큐와 달리 임의의 오프셋에서 데이터를 읽을 수 있다. 따라서 과거 데이터를 이용하여 처리를 시작할 수 있다.
예를 들어, 새롭게 마이크로서비스를 추가했을 때, 어느 정도 과거의 데이터로부터 처리를 시작할 수 있고, 일정 기간 정지하고 있는 서비스가 있어도, 재개했을 때에 정지한 타이밍까지의 데이터가 남아 있다 그러면 안전하게 처리를 재개할 수 있다.
큐가 아닌 것에 의한 복잡성
오프셋 기록
큐와 달리 데이터가 삭제되지 않는다는 것은 Consumer 측에서 자신이 어디까지 레코드를 처리했는지 기억해야 한다는 것을 의미하다. 따라서 Kafka의 Consumer 클라이언트는 오프셋을 기록하는 곳이 필요하다. Kafka의 프로토콜은 오프셋 기록 위치로 Kafka Broker를 이용한다. Kafka Broker는 무기한으로 데이터를 유지할 수 있으므로 각 클라이언트의 오프셋 정보를 기록하기 위한 스토리지로도 이용할 수 있다. 클라이언트가 어디까지 처리를 했는지의 오프셋(offset) 정보의 갱신도 이벤트의 하나이며, 그것이 계속 갱신되고 있는 이벤트 스트림이기도 한다. 이를 Kafka Broker 자체에 저장하고 클라이언트는 기동시에 해당 오프셋 정보를 토픽에서 읽는다. Broker에 남아 있는 가운데 최신 값이 지금까지 처리한 레코드의 오프셋이 된다.
참고로 AWS Kinesis는 DynamoDB를 사용하여 이러한 오프셋 정보를 기록한다.
Consumer Group
큐와 달라서 발생하는 복잡성의 영향은 오프셋 기록만이 아니다. Consumer의 처리에 의해 브로커의 데이터가 변화하지 않기 때문에, 만약 복수의 작업자(worker)가 같은 토픽을 처리하려고 하면, 오프셋(offset)의 기록만으로는 워커의 수만큼 중복해 같은 처리가 실행되어 버릴수 있다.
따라서 Kafka Consumer에는 Consumer Group이라는 개념이 존재한다. Consumer Group은 어떠한 목적으로 Kafka를 이용하고 있는지를 가리키는 집합이며, Consumer는 그것에 속해 Broker로부터 데이터를 얻는다.
동일한 Consumer Group에 속한 경우는 Kafka가 특정 토픽의 파티션은 해당 그룹 내에서 하나의 Consumer에서만 처리할 수 있다. (하나의 Consumer가 여러 파티션과 토픽을 처리 할 수 있다)
그림으로 보면 다음과 같다.
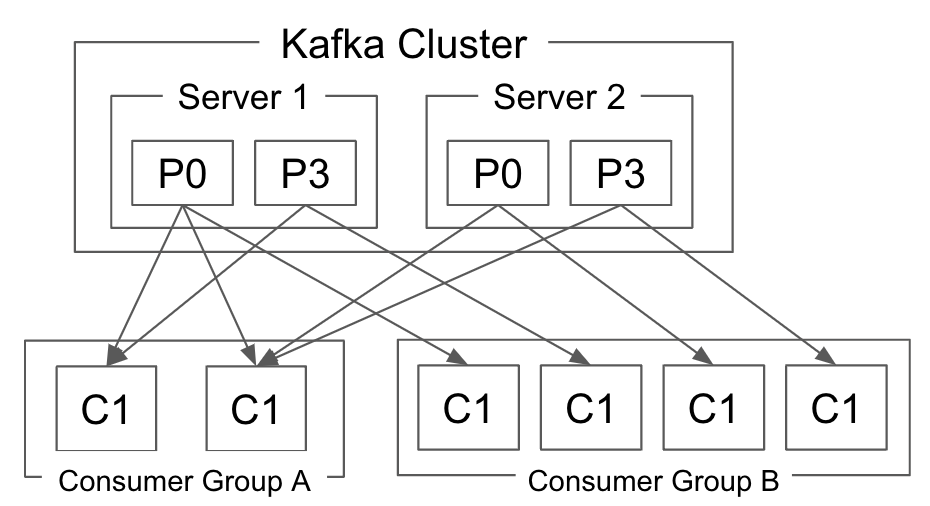
따라서 하나의 토픽의 파티션 총수 이상으로 해당 토픽을 처리하는 Consumer를 늘릴 수 없다. 파티션 수가 30이면 해당 주제를 처리할 수 있는 Consumer 수는 30개로 제한된다. 이 수는 총 인스턴스 수이며, 동일한 노드에 30개가 있는 것과 30개 노드에 하나씩 있는 것과는 동일하다.
Kafka Broker는 파티셔닝을 하지 않는다.
Kafka의 큰 특징 중 하나로 파티셔닝을 하는 주체가 Broker가 아니라는 점을 들 수 있다. Kafka에서 파티셔닝은 Producer에서 하게 된다.
데이터 소스가 Kafka Broker로 레코드를 보낼 때, 클라이언트 라이브러리 구현에 의해 파티션이 결정된다. 따라서 클라이언트 라이브러리가 다른 경우 파티셔닝 로직이 다를 수 있다. 예를 들어, Java Producer에서 디폴트 파티셔닝 로직은 키에 대해 murmur2에 의한 해시를 구하고, 그 결과를 파티션의 총수로 나누어 나머지를 이용한다. 반면, Ruby의 ruby-kafka라는 구현에서는 CRC32를 이용해 해시를 구해서 동일하게 나머지를 이용한다. 그리고, Ruby에는 그 외에 librdkafka라고 하는 C의 라이브러리의 바인딩하여 구현된 gem이 있어서 해시를 CRC32, murmur2, fnv1a 등으로 선택 가능하게 되어 있다. 이와 같이 동일한 데이터를 전송하더라도 클라이언트 구현에 따라 파티션 ID가 다를 수 있다.
또한, 엄밀히 말하면 레코드의 키와 파티셔닝은 직접적인 관련이 없다. 어디까지나 디폴트 동작으로 레코드의 키를 이용하는 것뿐이고, 클라이언트는 임의의 데이터를 임의의 로직으로 파티셔닝한 결과를 직접 레코드에 지정해 Broker에 넣는 것이 가능하다.
예를 들어, ruby-kafka를 사용하더라도, 내부에서 murmur2 해시를 이용하여 동일한 해시값를 구할 수 있으면, 이를 바탕으로 산출한 파티션을 직접 레코드에 지정하므로써 Java의 라이브러리와 동일한 파티션에 레코드를 보낼 수 있다.
파티셔닝 로직을 같게 하는 것은 실제 시스템에서 매우 중요하다.
예를 들어, 어느 한 사용자(ID:100)의 일일 액세스 수를 집계하려는 경우에는 ID:100 사용자의 레코드를 한 노드에서 처리되도록 해야 할 것이다. Consumer Group은 한 파티션의 데이터가 한 노드에서만 처리되도록 보장하므로, ID:100의 사용자 레코드가 일관되게 특정 파티션으로만 전송도 각 노드는 단순히 받은 데이터를 로컬로 집계 결과로 축적해 두면 된다. 이 때, 만약 새로운 데이터의 발생원이 추가되어 클라이언트 라이브러리의 구현이 다른 탓으로 파티셔닝의 결과가 갖추어지지 않게 되면, 집계 결과의 축적 장소가 엉망이 되어 버려, 올바르게 집계할 수 없게 될 것이다.
예를 들어, 어느 한 사용자(ID:100)의 일일 액세스 수를 집계하려고 할때, ID:100 사용자의 레코드를 한 노드에서 처리되도록 해야 하는 경우가 있을 수 있다. Consumer Group은 한 파티션의 데이터가 한 노드에서만 처리되도록 보장되므로, ID:100의 사용자 레코드가 일관되게 특정 파티션으로만 전송하도록 하게 되면, 각 노드는 단순히 받은 데이터를 하나의 로컬에로 집계 결과을 축적할 수 있게 된다. 이 때, 만약 새로운 데이터의 생산자가 추가되어 클라이언트 라이브러리의 구현이 달라서, 파티셔닝의 결과가 달라지게 되면, 집계 결과의 축적 장소가 각각 뿔뿔이 흩어지게 되어, 올바르게 집계할 수 없게 될 것이다.
이와 같이, 어떤 키와 어떤 알고리즘에 의해 그 토픽의 데이터가 파티셔닝되고 있는지를 파악하는 것은 매우 중요하다.
기본적으로는 공식 클라이언트의 구현인 murmur2을 이용한 파티셔닝에 맞춰 두는 것이 가장 안전할 수 있다고 생각된다.
파티션 수 산정의 중요성
Kafka Broker를 실제로 운영할 때 매우 어려운 요소는 파티션 수를 적절히 선택하는 것이다.
앞서 언급했듯이. 동일한 Consumer Group이 한 토픽의 파티션에서 하나의 클라이언트만 데이터를 받을 할 수 있다. 즉, 스케일 할 수 있는 클라이언트 수의 상한은 파티션 수에 의해 결정된다.
그렇다면, 파티션 수를 나중에 늘리면 되지 않을까? 라고 생각할지도 있다. 실제로는 그렇게 간단하지 않는 케이스도 많이 있다. 앞에서 파티셔닝 로직이 다른 클라이언트로 처리가 이동하게 되버리면 집계 처리가 올바르게 실행되지 않을 가능성이 있다고 설명했듯이, 파티션 수를 나중에 바뀌게 되면 같은 일이 발생한다 가능성이 있다.
파티셔닝은 기본적으로 키 값을 해시하여 토픽의 파티션 총 수로 나눈 나머지를 사용한다. 파티션의 총 수가 변경되면 동일한 데이터가 할당되는 파티션이 바뀌게 되고, 그렇게 되면 최종적으로 처리하고 있는 노드가 변화하게 되어 집계 처리가 틀어지게 되는 사태가 발생한다.
따라서, 나중에 파티션 수를 변경하는 것은 때로는 매우 까다로운 작업이 될 수 있다. 실제로 이 토픽을 얼마나 많은 수로 확장하고 싶은지 잘 생각하여 파티션 수를 산정하는 것이 매우 중요하다. 기본적인 산정 기준은 네트워크 처리량과 요구 사항으로 요구되는 처리 처리량 및 처리에 걸리는 대기 시간이다.
보충하자면, 처리 노드가 바껴도 집계 처리에 영향이 없도록 어플리케이션을 구축하면 되지 않을까라고 생각할지도 모른다. 그런데, 그렇게 하려면 스트림 프로세싱에 있어서는 너무 하고 싶지 않은 설계가 될 것이다. 왜냐하면, 스트림 프로세싱에 있어서의 집계에서는 배치 처리보다 훨씬 데이터 받아서 넣는 횟수가 많아지게 된다. 그 때문에 네트워크를 개입시켜 다른 노드에 데이터를 보관 유지하는 구조는 무시할 수 없는 레이턴시(latency:지연)의 증가를 초래하는 일이 있어, 반듯이 꼭 필요한 것이 아니라면, 결코 하지 싶지 않은 설계라고 할 수 있다. 이 점에 대한 자세한 내용은 이후의 다시 소개할 예정이다.
정리
Kafka는 실시간으로 대량의 이벤트 데이터를 처리하기 위한 플랫폼이며, 그 핵심을 이루는 것이 Kafka Broker라는 미들웨어이다.
이벤트 데이터는 사용자의 행동 로그, 시스템 간의 메시지 교환, 데이터베이스 변경 이력 또는 다양한 것들을 포함한다.
이벤트 데이터는 복수의 파티션으로 분할된 토픽에 저장된다. 저장된 데이터는 키와 값으로 구성된 레코드이며 내용은 단순한 바이트 열이다.
Kafka Broker는 큐와 달리 Consumer의 처리에 의해 데이터가 삭제되지 않기 때문에, 복수의 시스템에서 같은 토픽을 공유하거나, 과거에 거슬러 올라가 데이터를 처리하거나, 재시도하는 것이 용이하다.
한편, 자신이 어느 범위의 데이터를 처리 할 책임을 갖고 있는지는 클라이언트 스스로 인식해 둘 필요가 있어, 오프셋 기록이나 Consumer Group 등의 큐에는 없는 개념이 필요하게 되었다.
파티셔닝의 책임은 클라이언트가 가지므로, 파티션 결과에 의존하는 집계 처리 등을 실행할 때에는 클라이언트 라이브러리의 구현을 파악해 두는 것이 중요해진다.
참고
이 대부분의 내용은 공식 문서에 설명되어 있다.