Spring Batch 스케일링 및 병렬 처리 | 공식 레퍼런스 번역

Spring WebFlux, WebClient, WebSocket, RSocket.
스프링 배치 레퍼런스 문서 Version 5.0.0의 공식 레퍼런스를 한글로 번역한 문서이다.
스케일링 및 병렬 처리
많은 일괄 처리 문제는 단일 스레드 단일 프로세스 작업으로 해결할 수 있으므로 보다 복잡한 구현에 대해 생각하기 전에 요구 사항을 충족하는지 여부를 적절하게 확인하는 것이 좋다. 현실적인 작업의 성능을 측정하고 가장 간단한 구현이 먼저 필요를 충족하는지 확인한다. 표준 하드웨어에서도 수백 메가바이트의 파일을 1분도 걸리지 않고 읽고 쓸 수 있다.
여러 병렬 처리를 사용하여 작업 구현을 시작할 준비가 되면 Spring Batch 는 다양한 옵션을 제공한다. 이러한 옵션은 이 장에서 설명한다. 대략적으로 말하면, 병렬 처리에는 2개의 모드가 있다.
- 단일 프로세스, 멀티 스레드
- 멀티 프로세스
이들은 다음과 같이 카테고리로 분류된다.
- 멀티-스레드 단계 (single-process)
- 동시 단계 (single-process)
- 원격 단계의 청킹 (multi-process)
- 단계 분할 (single or multi-process)
먼저 단일 프로세스 옵션을 확인한다. 그런 다음 멀티 프로세스 옵션을 확인한다.
멀티-스레드 단계
병렬 처리를 시작하는 가장 쉬운 방법은 TaskExecutor 단계 구성에 추가하는 것이다.
예: 다음과 같이 속성을 tasklet에 추가할 수 있다.
<step id="loading">
<tasklet task-executor="taskExecutor">...</tasklet>
</step>
Java 구성을 사용하는 경우에는 다음 예제와 같이 단계에 TaskExecutor 추가할 수 있다.
Java Configuration
@Bean
public TaskExecutor taskExecutor() {
return new SimpleAsyncTaskExecutor("spring_batch");
}
@Bean
public Step sampleStep(TaskExecutor taskExecutor, JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("sampleStep", jobRepository)
.<String, String>chunk(10, transactionManager)
.reader(itemReader())
.writer(itemWriter())
.taskExecutor(taskExecutor)
.build();
}
예를 들면, taskExecutor는 TaskExecutor 인터페이스를 구현하는 다른 Bean 정의에 대한 참조이다. TaskExecutor(Javadoc)은 표준 Spring 인터페이스이다. 사용 가능한 구현에 대한 자세한 내용은 Spring 사용자 가이드를 참조하여라. 가장 간단한 멀티 스레드 TaskExecutor는 SimpleAsyncTaskExecutor이다.
위 구성의 결과fh Step는 별도의 실행 스레드에서 항목의 각 청크(Chunk: 각 커밋 간격)를 읽고, 처리하고, 쓰는 것을 의미한다. 이는 처리할 항목에 대해 고정된 순서가 없으며 청크에 단일 스레드 경우에 비해 연속적이지 않은 항목이 포함될 수 있음을 의미한다. 작업 실행자(Task Executre)에 의해 부과되는 제한(예: 스레드 풀에 의해 지원되고 있는지 여부) 외에도, tasklet의 구성에는 스로틀 제한(throttle-limit, 디폴트: 4)이 있다. 스레드 풀이 완전히 사용되도록 하려면 이 제한을 늘려야 할 수 있다.
throttleLimit
throttle은 사전적인 의미는 조절판이다. 생성된 쓰레드 중 몇개를 실제 작업에 사용할지를 결정한다.만약 10개의 쓰레드를 생성하고
throttleLimit을 4로 하였다면, 10개 쓰레드 중 4개만 배치에서 사용하게 됨을 의미한다.일반적으로
corePoolSize, maximumPoolSize, throttleLimit를 모두 같은 값으로 맞춘다.
예: 다음과 같이 throttle-limit을 늘릴 수 있다.
<step id="loading"> <tasklet
task-executor="taskExecutor"
throttle-limit="20">...</tasklet>
</step>
Java 구성을 사용하는 경우, 빌더는 다음과 같이 스로틀 제한에의 액세스를 제공한다.
Java Configuration
@Bean
public Step sampleStep(TaskExecutor taskExecutor, JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("sampleStep", jobRepository)
.<String, String>chunk(10, transactionManager)
.reader(itemReader())
.writer(itemWriter())
.taskExecutor(taskExecutor)
.throttleLimit(20)
.build();
}
또한 단계에서 사용되는 풀링된 리소스(DataSource 등)에 따라 동시성에 제한이 설정될 수 있다. 이러한 리소스의 풀은 최소한 단계에서 필요한 동시 스레드 수와 같아야 한다.
일부 일반적인 배치 사용 사례에서 멀티 스레드 Step 구현을 사용하는 데는 몇 가지 실질적인 제한이 있다.
Step의 많은 참여하는 객체(예 : reader, writer 등) 상태를 가진다(stateful). 상태를 스레드별로 분리되지 않으면, 이러한 컨포넌트를 멀티 스레드 Step에서 사용할 수 없다. 특히 Spring Batch의 대부분의 reader와 writer는 멀티 스레드에서 사용하도록 설계되지 않았다.
그러나 상태가 없거나(stateless) 또는 스레드 세이프(thread safe)한 reader와 writer를 사용할 수 있다. 또한 Spring Batch 샘플 [GitHub]에는 처리 식별자(Preventing State Persistence와 같은)를 사용하여 데이터베이스 입력 테이블에서 이미 처리된 항목을 추적하는 방법을 보여주는 샘플(parallelJob 이라고 함)이 있다.
Spring Batch는 다음 ItemWriter와 ItemReader와 같은 몇 가지 구현을 제공한다. 일반적으로 Javadoc 에는 thread safe 한지, 혹은 동시성 환경에서의 이슈를 회피하기 위해서 무엇을 해야 하는지가 기재되어 있다. Javadoc 에 정보가 없다면, 구현체에 상태가 있을지를 확인하면 된다. reader가 thread safe하지 않는다면, 제공되는 있는 SynchronizedItemStreamReader로 데코레이트 하는지, 독자적인 동기 델리게이터로 사용할 수 있다. read()에 대한 호출을 동기화하면 되고, process와 write가 청크의 가장 비용이 많이 드는 부분이라면, Step는 단일 스레드 구성보다 훨씬 빠르게 완료될 수 있다.
동시 단계 : Prallel Steps
병렬 처리가가 필요한 애플리케이션 로직을 개별 역할로 분할하고 개별 단계에 할당할 수 있는 한 단일 프로세스로 병렬화할 수 있다. Parallel Step을 실행하면 설정 및 사용이 간단하다.
예: 다음과 같이 한다면 단계 (step1,step2)와 step3를 병렬로 간단히 실행할 수 있다.
<job id="job1">
<split id="split1" task-executor="taskExecutor" next="step4">
<flow>
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>
<flow>
<step id="step3" parent="s3"/>
</flow>
</split>
<step id="step4" parent="s4"/>
</job>
<beans:bean id="taskExecutor" class="org.spr...SimpleAsyncTaskExecutor"/>
Java 구성을 사용한다면, 다음과 같이 단계 (step1,step2)와 step3 병렬로 간단히 실행할 수 있다.
Java Configuration
@Bean
public Job job(JobRepository jobRepository) {
return new JobBuilder("job", jobRepository)
.start(splitFlow())
.next(step4())
.build() //builds FlowJobBuilder instance
.build(); //builds Job instance
}
@Bean
public Flow splitFlow() {
return new FlowBuilder<SimpleFlow>("splitFlow")
.split(taskExecutor())
.add(flow1(), flow2())
.build();
}
@Bean
public Flow flow1() {
return new FlowBuilder<SimpleFlow>("flow1")
.start(step1())
.next(step2())
.build();
}
@Bean
public Flow flow2() {
return new FlowBuilder<SimpleFlow>("flow2")
.start(step3())
.build();
}
@Bean
public TaskExecutor taskExecutor() {
return new SimpleAsyncTaskExecutor("spring_batch");
}
구성 가능한 태스크 실행자는 개별 플로우를 실행하는 TaskExecutor 구현을 지정하는데 사용된다. 기본값은 SyncTaskExecutor이지만 단계를 병렬로 실행하려면 비동기식(asynchronous) TaskExecutor이 필요하다. 이 작업은 종료 상태를 집계하고 마이그레이션하기 전에 분할의 모든 흐름이 확실하게 완료된다.
자세한 내용은 흐름 분할(Split Flows) 섹션을 참조하여라.
Remote Chunking : 원격 청킹
원격 청킹(Remote Chunking)에서의 Step 처리는 여러 프로세스로 분할되어 여러 미들웨어를 통해 서로 통신한다. 다음 이미지는 이 패턴을 보여준다.
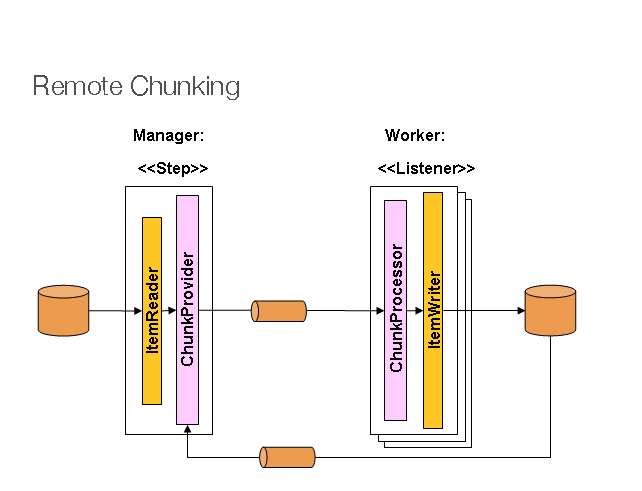
그림 1: 원격 청킹
매니저 구성 요소(manager component)는 단일 프로세스이고 작업자는 여러 원격 프로세스이다. 이 패턴은 매니저가 병목 현상이 없는 경우에 최적으로 작동하므로 처리 비용이 항목을 읽는 것보다 더 비싸다(실제로 자주 발생한다).
매니저는 미들웨어에 항목 청크를 메시지로 보내는 방법을 알고 있는 일반 버전으로 대체된 ItemWriter가 있는 Spring Batch Step의 구현이다. 워커(worker)는 사용중인 미들웨어(예 : JMS에서 MesssageListener 구현)의 표준 리스너이며 역할은 ChunkProcessor 인터페이스를 통해 표준 ItemWriter 또는 ItemProcessor를 사용하여, ItemWriter 항목의 청크를 처리하는 것이다. 이 패턴을 사용하는 장점 중 하나는 reader, proccessor , writer 구성 요소가 기성품이라는 것이다(단계를 로컬로 실행하는 데 사용되는 것과 동일). 항목은 동적으로 분할되고 미들웨어를 통해 작업이 공유되므로 리스너가 모두 열성적인 소비자인 경우 부하 분산(load balancing)이 자동으로 수행된다.
미들웨어는 내구성이 있어야 하며, 각 메시지를 하나의 컨슈머에 전달한다는 걸 보장해야 한다. JMS는 가장 명확한 후보이지만, 그리드 컴퓨팅 및 공유 메모리 제품 공간에 사용하는 다른 옵션(JavaSpaces 등)도 존재한다.
자세한 내용은 Spring Batch intergration - Remote Chunking을 참조하여라.
Partitioning : 파티셔닝
Spring Batch는 Step 실행을 분할하고 원격으로 실행하기 위한 SPI도 제공한다. 이 경우 원격 참여하는 객체는 Step 인스턴스이며 로컬 처리에 마찬가지로 구성 및 사용할 수 있다. 다음 이미지는 패턴을 보여준다.
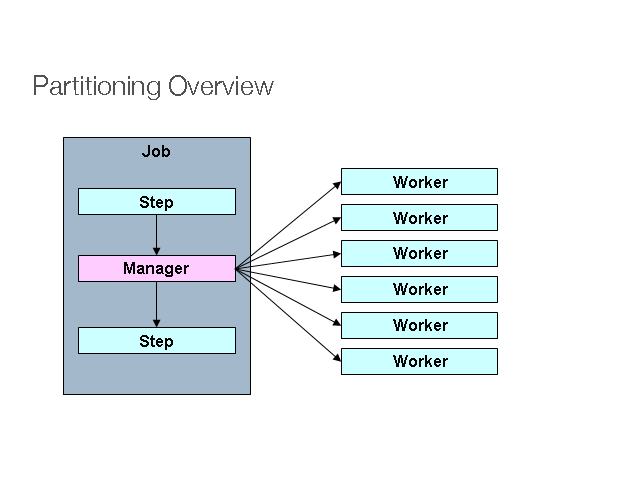
그림 2: 파티셔닝
왼쪽에 Job는 일련의 Step 인스턴스로 왼쪽에서 실행되며, Step 인스턴스 중 하나는 매니저로 표시되어 있다. 이 그림의 모든 워크는 Step의 동일한 인스턴스이며, 실제로 매니저를 대신하고 결과적으로 Job 동일한 결과가 된다. 작업자는 일반적으로 원격 서비스가 되지만 실행의 로컬 스레드가 될 수도 있다. 이 패턴으로 관리자가 작업자에게 보내는 메시지는 내구적이거나 전달은 보장할 필요가 없다. JobRepository에 있는 Spring Batch 메타 데이터를 사용하면 각 워커는 Job 각 실행에 대해 한 번만 실행된다.
Spring Batch의 SPI는 Step 특별한 구현체(PartitionStep 이라고 불린다)와, 특정의 환경에 따라 구현할 필요가 있는 두개의 전략 인터페이스로 구성된다. 전략 인터페이스는 PartitionHandler와 StepExecutionSplitter이며 다음 시퀀스 다이어그램은 이러한 역할을 보여준다.
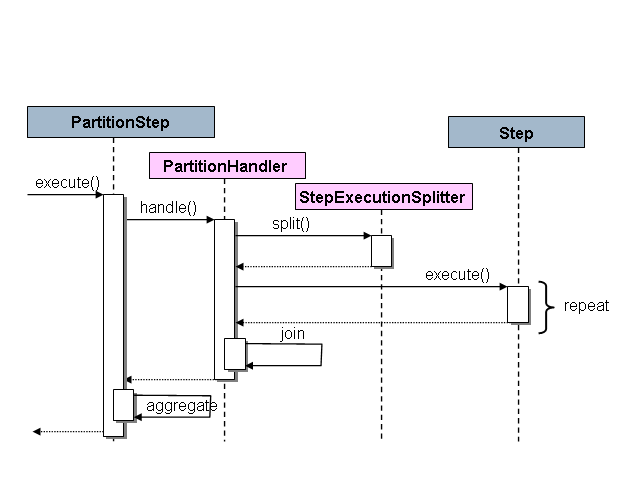
그림 3: 파티셔닝 SPI
이 경우 오른쪽에 Step은 “원격(remote)” 워커이므로, 이 역할을 수행하는 많은 객체와 프로세스가 있으며, 실행을 주도하는 PartitionStep 것으로 표시된다.
다음 예제는 XML 구성을 사용하는 경우의 PartitionStep 구성을 보여준다.
<step id="step1.manager">
<partition step="step1" partitioner="partitioner">
<handler grid-size="10" task-executor="taskExecutor"/>
</partition>
</step>
다음 예제는 Java 구성을 사용하는 경우의 PartitionStep 구성을 보여준다.
Java Configuration
@Bean
public Step step1Manager() {
return stepBuilderFactory.get("step1.manager")
.<String, String>partitioner("step1", partitioner())
.step(step1())
.gridSize(10)
.taskExecutor(taskExecutor())
.build();
}
멀티 스레드 단계의 throttle-limit 속성과 동일하게, grid-size 속성은 작업 실행자(task-executor)가 단일 Step에 요청으로 너무 많은 요청이 보내지 못하도록 할 수 있다.
멀티 스레드 단계의 throttleLimit 메소드와 동일하게, gridSize 메소드는 작업 실행자(task-executor)가 단일 Step에 요청으로 너무 많은 요청이 보내지 못하도록 할 수 있다.
Spring Batch 샘플 [GitHub] 단위 테스트 스위트(unit test suite: partition*Job.xml 구성 참조)에 간단한 예시가 있으니, 복사하여 확장해서 사용화면 된다.
를 복사하여 확장할 수 있는 간단한 예가 있다.
Spring Batch는 step1:partition0라는 파티션의 단계 실행을 작성한다. 많은 사람들이 일관성을 위해 관리자의 단계를 step1:manager라고 부르는 것을 선호한다. Step에 별칭을 사용할 수 있다(id 속성 대신 name 속성을 지정).
PartitionHandler
PartitionHandler는 원격 또는 그리드 환경의 구조를 인식하는 구성 요소이다. DTO와 같은 패브릭(fabric) 특정 형식으로 래핑된 원격 Step 인스턴스로 StepExecution 요청을 보낼 수 있다. 입력 데이터를 분할하는 방법이나 여러 Step 실행의 결과를 집계하는 방법을 알 필요는 없다. 일반적으로 말하자면, 탄력성과 페일오버는 패브릭의 기능이기 때문에, 그들에 대해 알 필요는 없다. 어쨌든 Spring Batch는 패브릭에 관계없이 항상 재시작 가능한 주조를 제공한다. 실패한 Job 경우는 언제든지 다시 시작할 수 있으며, 이 경우에는 실패한 Step만 다시 실행한다.
PartitionHandler 인터페이스는 단순한 RMI 원격 처리, EJB 원격 처리, 커스텀 웹 서비스, JMS, Java Spaces, 공유 메모리 그리드(Terracotta, Coherence 등), 그리드 실행 패브릭(GridGain 등) 등 다양한 패브릭 유형에 특화된 구현 를 가질 수 있다. Spring Batch 에는 독자적인 그리드 또는 원격 패브릭의 구현은 포함되어 있지 않다.
다만, Spring Batch 는 Spring의 TaskExecutor 전략을 사용하여, 각 Step 인스턴스를 개별의 실행 여러 thread로 로컬에 실행하는 PartitionHandler 편리한 구현을 제공한다. 구현을 TaskExecutorPartitionHandler라고 한다.
TaskExecutorPartitionHandler는 앞에서 설명한 XML 네임스페이스로 구성된 단계의 기본값이다. 다음과 같이 명시적으로 구성할 수도 있다.
<step id="step1.manager">
<partition step="step1" handler="handler"/>
</step>
<bean class="org.spr...TaskExecutorPartitionHandler">
<property name="taskExecutor" ref="taskExecutor"/>
<property name="step" ref="step1" />
<property name="gridSize" value="10" />
</bean>
다음과 같이 Java 구성을 사용하여 TaskExecutorPartitionHandler 명시적으로 구성할 수 있다.
Java Configuration
@Bean
public Step step1Manager() {
return stepBuilderFactory.get("step1.manager")
.partitioner("step1", partitioner())
.partitionHandler(partitionHandler())
.build();
}
@Bean
public PartitionHandler partitionHandler() {
TaskExecutorPartitionHandler retVal = new TaskExecutorPartitionHandler();
retVal.setTaskExecutor(taskExecutor());
retVal.setStep(step1());
retVal.setGridSize(10);
return retVal;
}
gridSize 속성은 stepdmf 몇개로 나눠서 실행하는 결정하므로 TaskExecutor 스레드 풀 사이즈와 일치시킬 수 있다. 또는 사용 가능한 스레드 수보다 크게 설정하여 작업 블록을 줄일 수 있다.
TaskExecutorPartitionHandler 대량의 파일 복사 및 콘텐츠 관리 시스템에 파일 시스템 복제 등 IO 처리가 많은 Step 인스턴스에 유용하다. 원격 호출 (Spring Remoting 의 사용 등)의 프록시인 Step 구현을 제공하는 것으로써, 리모트의 실행에도 사용할 수 있다.
Partitioner : 파티셔너
Partitioner 역할은 간단하다. 새로운 Step 실행 전용 입력 매개 변수로 실행 컨텍스트를 생성한다(재시작에 대해 걱정할 필요가 없다). 다음과 같이 인터페이스 정의에서 알 수 있듯이 단일 메소드가 있다.
public interface Partitioner {
Map<String, ExecutionContext> partition(int gridSize);
}
이 메서드의 반환 값은 각 단계 실행의 고유 이름(String)을 ExecutionContext 형식의 입력 매개 변수와 연결한다. 이름은 나중에 분할된 StepExecutions단계 이름으로 배치 메타데이터에 표시된다. ExecutionContext는 단순히 키-값 쌍으로 저장하므로 일련의 기본 키(primary key), 행 번호 또는 입력 파일의 위치가 포함될 수 있다. 다음에, 리모트 Step는 통상, 다음의 섹션으로 설명하였 듯이, #{…} 플레이스홀더(StepScope서의 지연 바인딩)를 사용해 문맥 입력에 바인드 한다.
Step 실행의 이름(Partitioner에 의해 반화하는 Map의 키)은 Job 안에 step 실행중에서 유일해야 한다는 필요는 있고, 그 외의 특정의 제약은 없다. 이를 수행하기 위한 (그리고 이름을 사용자에게 의미있는 것으로 만들려면) 가장 쉬운 방법은 접두사와 접미사 명명 규칙을 사용하는 것이다. 접미사는 단순한 카운터이다. 프레임워크에는 이 규칙을 사용할 SimplePartitioner를 제공한다.
PartitionNameProvider 인터페이스를 사용하여 파티션 이름을 파티션 자체와 별도로 지정할 수 있다. Partitioner가 이 인터페이스를 구현하는 경우 재시작할 시에 이름만 조회된다. 파티셔닝이 부하가 있는 경우라면 이는 유용한 최적화가 될 수 있다. PartitionNameProvider에서 제공하는 이름은 Partitioner 제공된 이름과 일치해야 한다.
Binding Input Data to Steps : 입력 데이터를 단계에 바인딩
PartitionHandler에 의해 수행되는 단계가 동일한 구성을 가지며, 런타임 시에 ExecutionContext로 부터 입력 매개변수가 바인딩되는 것은 매우 효율적이다. 이는 Spring Batch의 StepScope기능을 사용하여 쉽게 수행 할 수 있다(지연 바인딩 섹션에서 자세히 설명 함). 예를 들어, Partitioner가 각 step 호출에 대해 다른 파일(또는 디렉터리)을 가리키는 fileName 속성 키를 사용하여, ExecutionContext 인스턴스를 생성하는 경우에는 Partitioner 출력은 다음 표의 내용과 유사할 수 있다.
표 1: 디렉터리 처리를 대상 Partitioner 으로 제공되는 실행 컨텍스트에 대한 단계 실행 이름의 예
| 단계 실행 이름(키) | ExecutionContext(값) |
|---|---|
| filecopy:partition0 | fileName =/home/data/one |
| filecopy:partition1 | fileName =/home/data/two |
| filecopy:partition2 | fileName =/home/data/three |
그런 다음 실행 컨텍스트에 지연 바인딩을 사용하여 파일 이름을 단계에 바인딩할 수 있다.
다음 예제에서는 XML에서 지연 바인딩을 정의하는 방법을 보여 준다.
XML Configuration
<bean id="itemReader" scope="step"
class="org.spr...MultiResourceItemReader">
<property name="resources" value="#{stepExecutionContext[fileName]}/*"/>
</bean>
다음의 예제는 Java 로 지연 바인딩을 정의하는 방법을 나타내고 있다.
Java Configuration
@Bean
public MultiResourceItemReader itemReader(
@Value("#{stepExecutionContext['fileName']}/*") Resource [] resources) {
return new MultiResourceItemReaderBuilder<String>()
.delegate(fileReader())
.name("itemReader")
.resources(resources)
.build();
}