Kotest 데이터 기반 테스트(Data-Driven Testing)
데이터 기반 테스트
데이터 기반 테스트(Data-Driven Testing)는 동일한 테스트 코드를 여러 데이터 집합에 대해 반복하여 실행하는 방법으로, Junit5의 매개변수화(Parameterized) 테스트와 유사하다. 서로 다른 입력 데이터로 여러 테스트를 작성하는 대신 단일 테스트 케이스에 여러 입력을 제공하여 여러 테스트를 확인할 수 있다.
논리 기반 테스트를 작성할 때는 특정 시나리오에서 작동하는 한두 개의 특정 코드 경로가 적합한다. 다른 경우에는 예제 기반 테스트가 더 많으며 다양한 매개변수 조합을 테스트하는 것이 도움이 될 수 있다.
이러한 상황에서 데이터 기반 테스트(테이블 기반 테스트라고도 함)는 지루한 상용구를 피할 수 있는 쉬운 기법이다.
Kotest는 프레임워크에 내장된 데이터 중심 테스트를 일급 객체(First class)으로 지원을 제공한다. 이는 사용자가 제공한 입력 값을 기반으로 테스트 케이스 항목을 자동으로 생성한다.
데이터 기반 테스트 시작하기
간단한 예를 통해서 데이터 기반 테스트에 대해서 알아보겠다.
피타고라스의 삼각형 테스트
입력 값이 유효한 삼각형(a 제곱 + b 제곱 = c 제곱)인 경우, true을 반환하는 피타고라스의 삼각형 함수에 대한 테스트를 작성해 보겠다.
fun isPythagTriple(a: Int, b: Int, c: Int): Boolean = a * a + b * b == c * c
행(Row)당 하나 이상의 요소가 필요하므로(3개 필요), 값의 단일 Row(이 경우 두 개의 입력과 예상 결과)을 보유할 데이터 클래스를 정의하는 것부터 시작한다.
data class PythagTriple(val a: Int, val b: Int, val c: Int)
이 데이터 클래스의 인스턴스를 사용하여 테스트를 생성하고, 주어진 행에 대한 테스트 로직을 수행하는 람다를 받아들이는 withData 함수에 전달한다.
예를 들어:
package com.devkuma.kotest.tutorial.datadriven
import io.kotest.core.spec.style.FunSpec
import io.kotest.datatest.withData
import io.kotest.matchers.shouldBe
class PythagTripleTest : FunSpec({
context("Pythag triples tests") {
withData(
PythagTriple(3, 4, 5),
PythagTriple(6, 8, 10),
PythagTriple(8, 15, 17),
PythagTriple(7, 24, 25)
) { (a, b, c) ->
isPythagTriple(a, b, c) shouldBe true
}
}
})
데이터 클래스를 사용하기 때문에 입력 row이 멤버 속성으로 재구성될 수 있다. 이를 실행하면 입력에 각 입력 행마다 하나씩 총 4개의 테스트 케이스가 생성된다.
Kotest는 각 입력 행에 대해 별도의 테스트 케이스를 수동으로 작성한 것처럼 각 입력 행에 대한 테스트 케이스를 자동으로 생성한다.
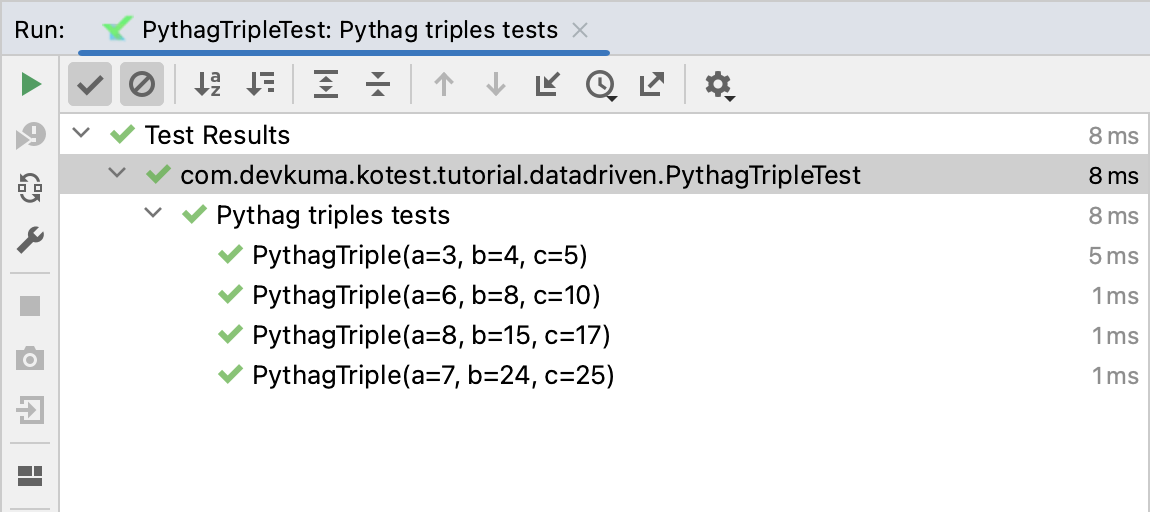
테스트 이름은 데이터 클래스 자체에서 생성되지만 사용자 지정할 수 있다.
특정 입력 행에 오류가 있는 경우 테스트가 실패하고 Kotest는 실패한 값을 출력한다. 예를 들어, 이전 예제에서 PythagTriple(5, 4, 3) 행을 포함하도록 변경하면 해당 테스트는 실패로 표시된다.
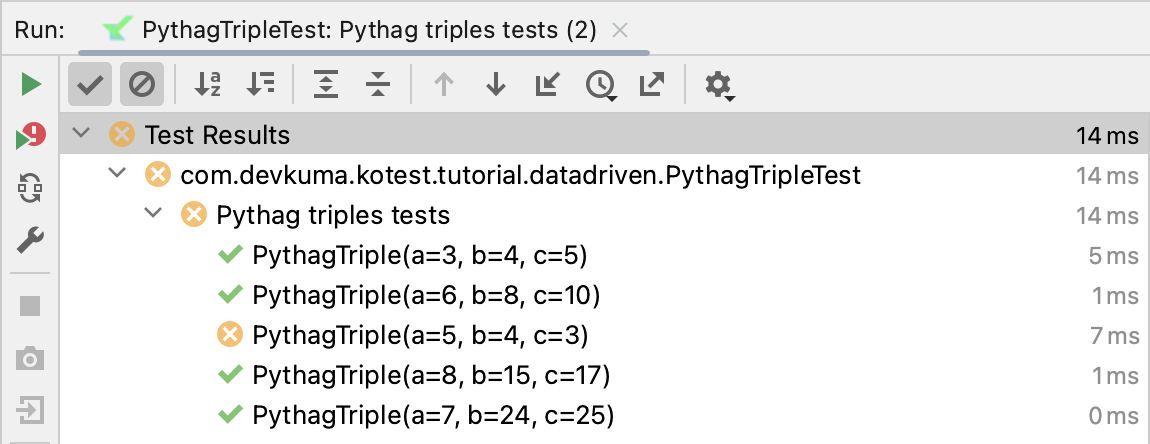
오류 메시지에는 오류와 입력 행 세부 정보가 포함된다:
expected:<true> but was:<false>
Expected :true
Actual :false
상세하게는 a=5, b=4, c=3 일 때, 5 * 5 + 4 * 4 = 41와 3 * 3 = 9는 같지 않기 때문에 false가 반환되어서 실패가 되었다.
이전 예제에서는 부모 테스트에서 withData 호출을 래핑했기 때문에 테스트 결과가 표시될 때 추가 컨텍스트(context("Pythag triples tests"))가 있다. 구문은 사용된 스펙 스타일에 따라 달라진다. 여기서는 컨테이너에 컨텍스트 블록을 사용하는 재미있는 스펙을 사용했다. 실제로 데이터 테스트는 컨테이너 안에 얼마든지 중첩할 수 있다.
그러나 이는 선택 사항이며, 루트 수준(level)에서도 데이터 테스트를 정의할 수 있다.
예를 들어:
class PythagTripleTest : FunSpec({
withData(
PythagTriple(3, 4, 5),
PythagTriple(6, 8, 10),
//PythagTriple(5, 4, 3),
PythagTriple(8, 15, 17),
PythagTriple(7, 24, 25)
) { (a, b, c) ->
isPythagTriple(a, b, c) shouldBe true
}
})
다양한 값에 대한 테스트
또 다른 예로 다양한 타입의 데이터들의 테스트 예제는 아래와 같다:
package com.devkuma.kotest.tutorial.datadriven
import io.kotest.core.spec.style.FunSpec
import io.kotest.datatest.withData
import io.kotest.matchers.shouldBe
class WithDataTest : FunSpec({
context("문자열 길이 검증") {
withData(
ValueExpected("Hello", 5), // 첫 번째 데이터 세트: 문자열 "Hello"
ValueExpected("World", 5) // 두 번째 데이터 세트: 문자열 "World"
) { (str, expected) ->
str.length shouldBe expected // 각 데이터 세트에 대해 문자열의 길이가 기대값인 확인
}
}
context("집합 크기 검증") {
withData(
ValueExpected(setOf(1, 2, 3), 3), // 첫 번째 데이터 세트: 정수 집합 {1, 2, 3}
ValueExpected(setOf(4, 5, 6, 7), 4) // 두 번째 데이터 세트: 정수 집합 {4, 5, 6, 7}
) { (set, expected) ->
set.size shouldBe expected // 각 데이터 세트에 대해 집합의 크기가 기대값인 확인
}
}
context("맵 크기 검증") {
withData(
ValueExpected(mapOf("a" to 1, "b" to 2), 2), // 첫 번째 데이터 세트: 맵 {"a" -> 1, "b" -> 2}
ValueExpected(mapOf("x" to 10, "y" to 20, "z" to 30), 3) // 두 번째 데이터 세트: 맵 {"x" -> 10, "y" -> 20, "z" -> 30}
) { (map, expected) ->
map.size shouldBe expected // 각 데이터 세트에 대해 맵의 크기가 기대값인 확인
}
}
})
data class ValueExpected<T>(
val value: T,
val expected: Int,
)
forAll 함수 사용
데이터 검증을 위해 forAll 함수를 사용하여 데이터 주도 테스트를 수행할 수도 있다.
package com.devkuma.kotest.tutorial.datadriven
import io.kotest.core.spec.style.StringSpec
import io.kotest.data.forAll
import io.kotest.data.row
import io.kotest.matchers.shouldBe
class ForAllTest : StringSpec({
"문자열 길이 검증" {
forAll(
row("Hello", 5),
row("World", 5)
) { str, expected ->
str.length shouldBe expected
}
}
"집합 크기 검증" {
forAll(
row(setOf(1, 2, 3), 3),
row(setOf(4, 5, 6, 7), 4)
) { set, expected ->
set.size shouldBe expected
}
}
"맵 크기 검증" {
forAll(
row(mapOf("a" to 1, "b" to 2), 2),
row(mapOf("x" to 10, "y" to 20, "z" to 30), 3)
) { map, expected ->
map.size shouldBe expected
}
}
})
위의 예제에서는 forAll 함수를 사용하여 정수 데이터를 생성하고, 해당 데이터를 통해 테스트를 반복적으로 실행하고 있다.
Callbacks
데이터 기반 테스트에서 전후 콜백을 사용하려면 표준 beforeTest / afterTest를 사용할 수 있다. 데이터 기반 테스트를 사용하여 만든 모든 테스트는 일반 테스트와 동일한 방식으로 작동하므로 모든 표준 콜백은 모든 테스트를 직접 작성한 것처럼 동작한다.
예를 들어:
package com.devkuma.kotest.tutorial.datadriven
import io.kotest.core.spec.style.FunSpec
import io.kotest.datatest.withData
class CallbackTest : FunSpec({
beforeTest {
println("beforeTest")
}
context("callback test") {
withData("X", "Y", "Z") { a ->
println(a)
}
}
})
다음은 예제를 실행한 결과이다:
beforeTest
beforeTest
X
beforeTest
Y
beforeTest
Z
데이터 테스트 이름
기본적으로 각 테스트의 이름은 단순히 입력 행의 toString()이다. 이는 일반적으로 JVM의 데이터 클래스에서 잘 작동하지만 입력 행이 안정적이어야 한다.
그러나, 안정적인 데이터 클래스를 사용하지 않거나 JVM이 아닌 대상에서 실행하는 경우 또는 단순히 사용자 지정하려는 경우 테스트 이름을 생성하는 방법을 지정할 수 있다.
안정적인 이름
테스트를 생성할 때 Kotest는 테스트 스위트를 실행하는 동안 안정적인 테스트 이름이 필요하다. 테스트 이름은 Gradle 또는 Intellij에 테스트 상태를 알릴 때 테스트를 가리키는 식별자의 기초로 사용된다. 이름이 안정적이지 않으면 ID가 변경되어 테스트가 나타나지 않거나 완료되지 않은 것처럼 보이는 오류가 발생할 수 있다.
Kotest는 입력 클래스의 toString() 값이 안정적이라고 판단되는 경우에만 입력 클래스의 toString()을 사용하고 그렇지 않은 경우 클래스 이름을 사용한다.
@IsStableType으로 유형에 어노테이션을 추가하여 Kotest가 테스트 이름에 toString()을 사용하도록 강제할 수 있다. 그러면 이에 관계없이 toString()이 사용된다.
또는 테스트의 표시 이름을 완전히 사용자 지정할 수 있다.
mapOf 사용
Kotest에서는 키가 테스트 이름이고 값이 해당 행의 입력 값인 withData 함수에 맵을 전달하여 테스트 이름을 지정할 수 있다.
package com.devkuma.kotest.tutorial.datadriven
import io.kotest.core.spec.style.FunSpec
import io.kotest.datatest.withData
import io.kotest.matchers.shouldBe
class PythagTripleMapOfTest : FunSpec({
context("Pythag triples tests") {
withData(
mapOf(
"3, 4, 5" to PythagTriple(3, 4, 5),
"6, 8, 10" to PythagTriple(6, 8, 10),
"8, 15, 17" to PythagTriple(8, 15, 17),
"7, 24, 25" to PythagTriple(7, 24, 25)
)
) { (a, b, c) ->
a * a + b * b shouldBe c * c
}
}
})
테스트 이름 함수
또는 행을 입력으로 받아 테스트 이름을 반환하는 함수를 withData에 전달할 수 있다. Kotlin 유형 추론이 얼마나 관대하게 느껴지느냐에 따라 withData 함수에 유형 매개 변수를 지정해야 할 수도 있다.
package com.devkuma.kotest.tutorial.datadriven
import io.kotest.core.spec.style.FunSpec
import io.kotest.datatest.withData
import io.kotest.matchers.shouldBe
class PythagTripleNameTest : FunSpec({
context("Pythag triples tests") {
withData<PythagTriple>(
nameFn = { "${it.a}, ${it.b}, ${it.c}" },
PythagTriple(3, 4, 5),
PythagTriple(6, 8, 10),
PythagTriple(8, 15, 17),
PythagTriple(7, 24, 25)
) { (a, b, c) ->
a * a + b * b shouldBe c * c
}
}
})
이 예제의 출력은 이제 조금 더 명확해졌다:
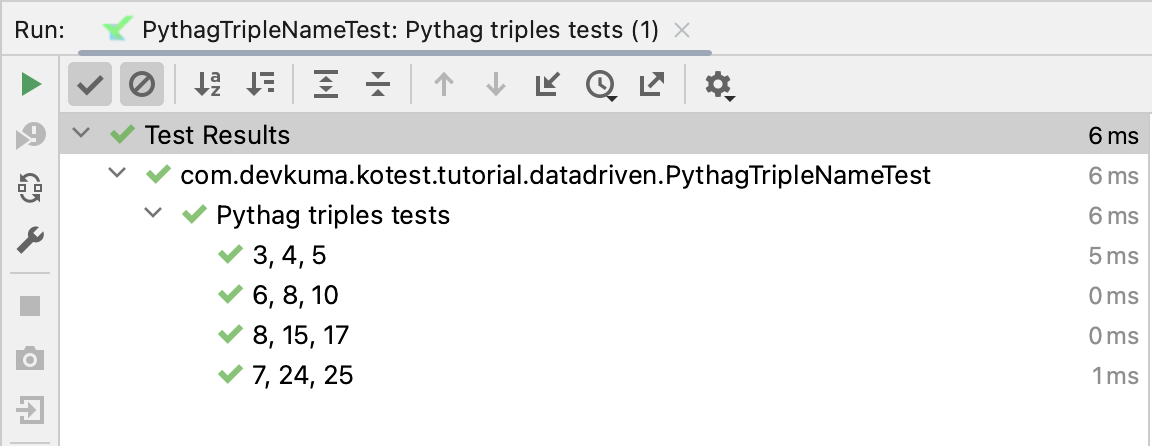
WithDataTestName
또 다른 대안은 WithDataTestName 인터페이스를 구현하는 것이다. 이 인터페이스를 제공하면 toString()이 사용되지 않고 대신 각 행에 대해 해당 인터페이스의 dataTestName() 함수가 호출된다.
package com.devkuma.kotest.tutorial.datadriven
import io.kotest.datatest.WithDataTestName
data class PythagTriple(val a: Int, val b: Int, val c: Int) : WithDataTestName {
override fun dataTestName() = "wibble $a, $b, $c wobble"
}
이 예제의 출력으로 좀 더 간단해졌다:
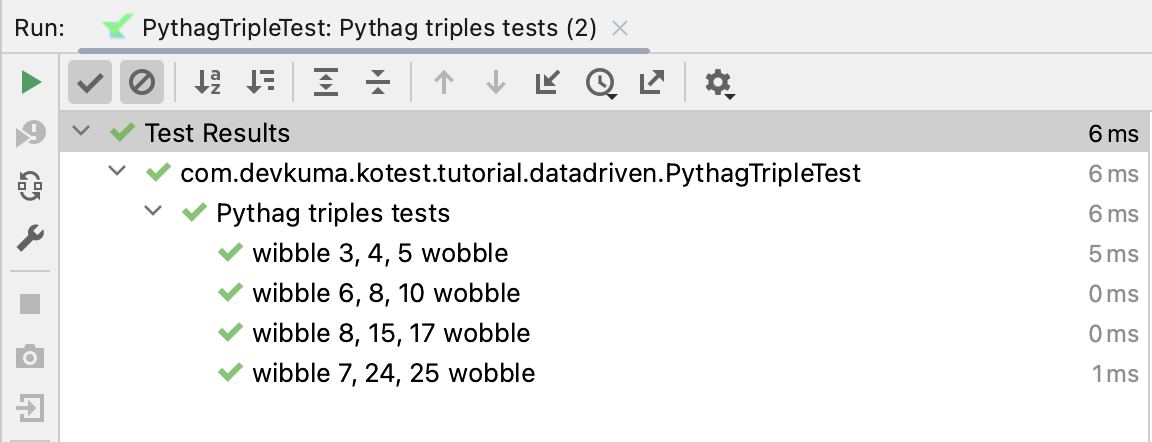
중첩 데이터 테스트
Kotest의 데이터 테스트는 매우 유연하며 데이터 테스트 구성을 무제한으로 중첩할 수 있다. 각 추가 중첩은 테스트 출력에 또 다른 중첩 레이어를 생성하여 모든 입력의 카르테시안 조인(cartesian join)을 제공한다.
예를 들어, 다음 코드 스니펫에는 두 개의 중첩 레이어가 있다.
package com.devkuma.kotest.tutorial.datadriven
import io.kotest.core.spec.style.FunSpec
import io.kotest.datatest.withData
class NestedDataTest : FunSpec({
context("each service should support all http methods") {
val services = listOf(
"http://internal.foo",
"http://internal.bar",
"http://public.baz",
)
val methods = listOf("GET", "POST", "PUT")
withData(services) { service ->
withData(methods) { method ->
// test service against method
}
}
}
})
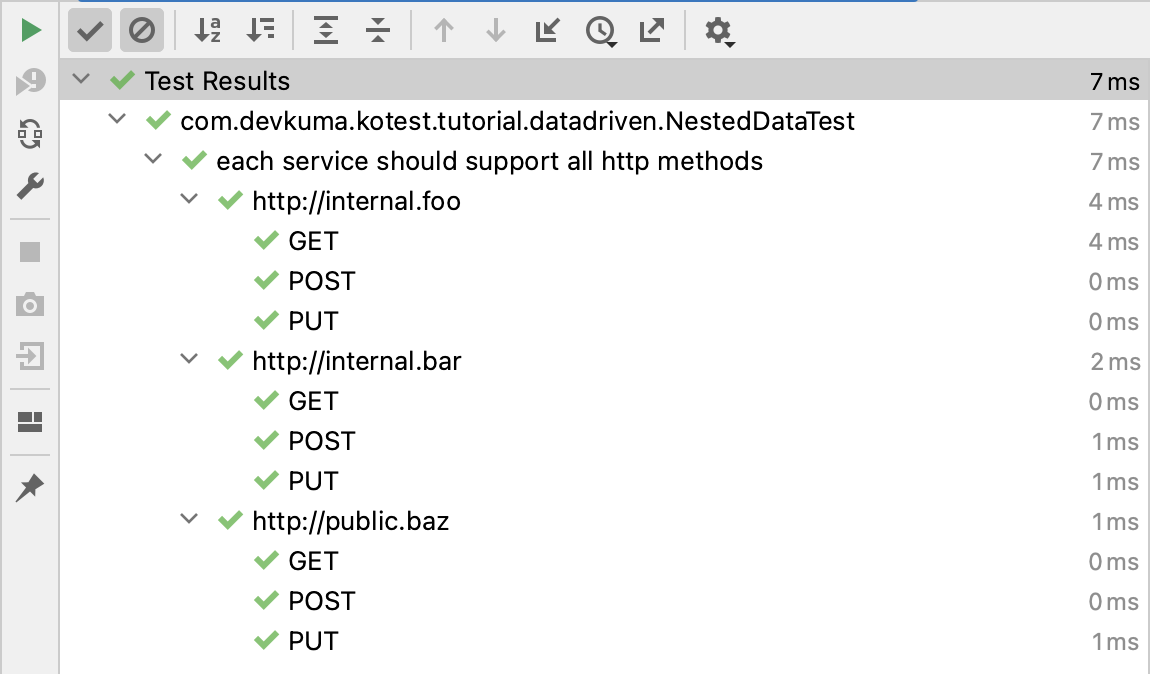
다음은 동일한 예제이지만, 이번에는 두 번째 레벨에 사용자 지정 테스트 이름을 추가한 예제이다:
package com.devkuma.kotest.tutorial.datadriven
import io.kotest.core.spec.style.FunSpec
import io.kotest.datatest.withData
class NestedDataTest2 : FunSpec({
context("each service should support all http methods") {
val services = listOf(
"http://internal.foo",
"http://internal.bar",
"http://public.baz",
)
val methods = listOf("GET", "POST", "PUT")
withData(services) { service ->
withData<String>({ "should support HTTP $it" }, methods) { method ->
// test service against method
}
}
}
})
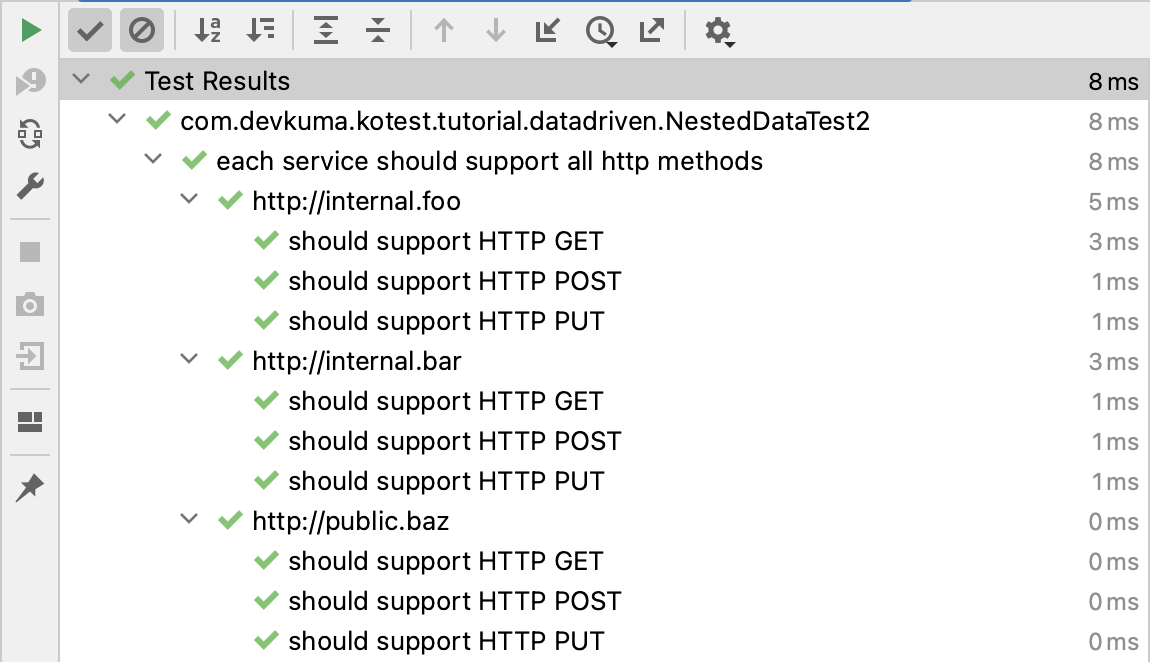
그밖에 데이터 테스트
앞에서는 withData 함수를 사용한 테스트는 설명하였다. 여기서는 kotest에 기본 데이터 활용 방법에 대해서 설명한다.
테스트 데이터 생성
테스트 데이터를 생성하는 것은 테스트의 신뢰성과 완전성을 보장하는 데 중요한 역할을 한다. Kotest에서는 다양한 방법을 사용하여 테스트 데이터를 생성할 수 있다. 예를 들어, 테스트 함수 내에서 직접 데이터를 정의하거나, 테스트 케이스 클래스 내에서 멤버 변수로 데이터를 정의할 수 있다.
package com.devkuma.kotest.tutorial.datadriven
import io.kotest.core.spec.style.StringSpec
import io.kotest.matchers.shouldBe
class DataTest : StringSpec({
val testData = listOf(1, 2, 3, 4, 5)
"사전 정의된 테스트 데이터를 사용하여 테스트" {
testData.size shouldBe 5
}
"범위 내에서 테스트 데이터를 사용하여 테스트" {
val generatedData = (1..10).toList()
generatedData.size shouldBe 10
}
})
위의 예제에서는 testData라는 멤버 변수를 사용하여 테스트 데이터를 정의하고 있다. 또한 generatedData를 사용하여 범위 내에서 데이터를 생성하고 있다.
테스트 데이터 세팅과 정리
테스트가 실행되기 전에 필요한 데이터를 세팅하고, 테스트가 완료된 후에는 데이터를 정리하는 것은 테스트의 안정성을 보장하는 데 중요한다. Kotest에서는 beforeTest와 afterTest 블록을 사용하여 테스트 데이터의 세팅과 정리를 수행할 수 있다.
package com.devkuma.kotest.tutorial.datadriven
import io.kotest.core.spec.style.StringSpec
class DataSetupAndCleanupTest : StringSpec({
val database = setupDatabase()
beforeTest {
database.connect()
}
afterTest {
database.disconnect()
}
"Test with database connection" {
// 데이터베이스 연결을 사용한 테스트 로직
}
})
fun setupDatabase(): Database {
// Setup database and return
}
위의 예제에서는 beforeTest 블록에서 데이터베이스에 연결하고, afterTest 블록에서 연결을 해제하고 있다.
테스트 데이터의 생성, 관리 및 정리는 테스트의 신뢰성을 확보하는 데 중요한 요소이다. Kotest를 사용하여 테스트 데이터를 효과적으로 관리하면 안정적이고 견고한 테스트를 수행할 수 있으며, 소프트웨어의 품질을 향상시킬 수 있다.