HBase 데이터 모델
데이터 구조
HBase 테이블에는 형식이 없으며 바이트 배열(byte[ ])로 저장된다.
HBase 행은 고유한 행 키로 오름차순으로 정렬되며 테이블의 값을 읽고 쓸 때 이 행 키를 통해 수행된다.
앞에서 언급했지만 HBase에서 관리하는 데이터는 일정 범위마다 리전이라는 단위로 분할되어 있으며 테이블에는 여러 리전이 있다.
또한 HBase 열은 열 패밀리라는 단위로 그룹화된다.
테이블의 데이터는 리전별로 나뉘어지고, 열 패밀리마다 나뉘어져 파일로 내보내진다.
파일은 별도이거나 동일한 리전이면, 동일한 Region 서버에 저장된다.
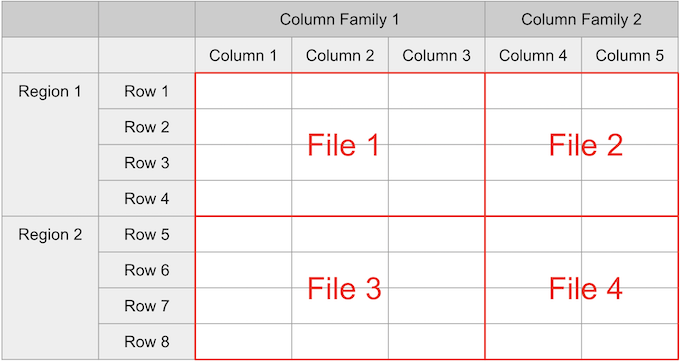
HBase 데이터(셀 값)에는 각각 타임스탬프가 부여되어 있어 버전을 관리하고 있다. 파일은 다음과 같은 형식으로 저장된다.
Row(Row Key): Column family: Column: timestamp: 값
데이터 모델
Apache HBase 데이터 모델은 열(Column) key, 행(Row) key이 및 타임스탬프에 의해 색인이 생성되는 분산형, 다차원형, 영구형 및 정렬된 증폭기이며, 이것이 Apache HBase가 키-값 스토리지 시스템이라고도 불리는 이유이다.
HBase의 기본 단위는 컬럼이고 이 컬럼들이 모여서 컬럼 패밀리(Column Family)를 구성하고, 이 컬럼 패밀리가 모여서 테이블을 구성한다. 테이블에 들어가는 각 Row는 Row Key를 가지고 식별 할 수 있다. 아래 그림을 보자.
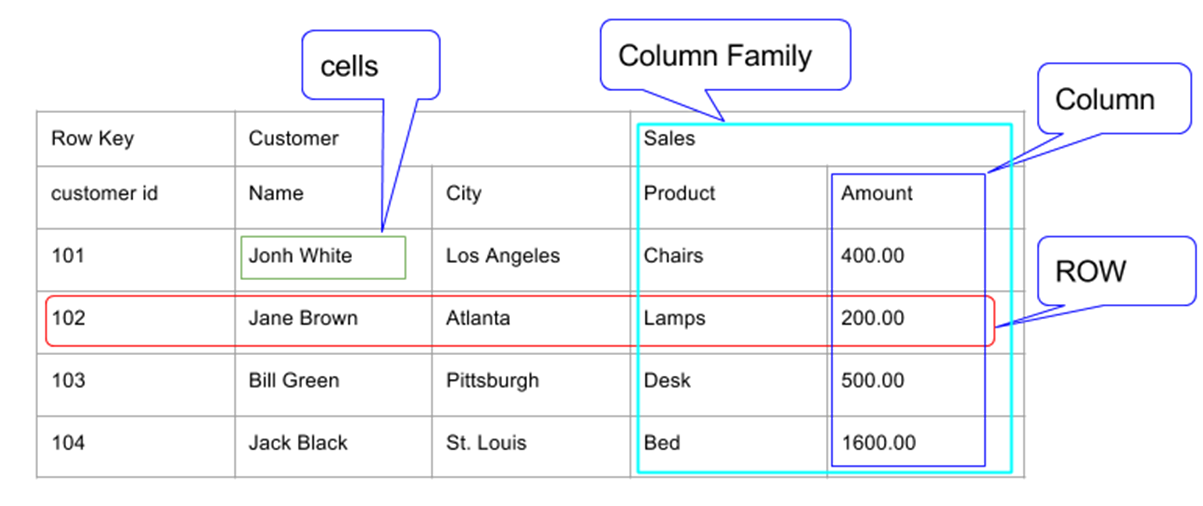
- 이 테이블은 Customer와 Sales 두 개의 컬럼 패밀리를 가지고 있다.
- Customer 컬럼 패밀리는 Name과 City 두 개의 컬럼을 가지고 있다.
- Sales 컬럼 패밀리는 Product와 Amount 두 개의 컬럼을 가지고 있다.
- Row는 Row Key, Customer CF, Sales CF로 구성된다.
다음은 Apache HBase에서 사용되는 데이터 모델 용어이다.
Table
Apache HBase 테이블은 여러 Row로 구성된다. 문자로 구성되고 파일 시스템과 함께 사용하기 쉬운 테이블로 데이터를 구성한다.
- Row들의 집합 (Row Key가 있으며 다수의 column family로 구성).
- Schema 정의서 Column Family 만 정의.
Row
Apache HBase는 행(Row)을 기반으로 데이터를 저장하고, 각 행에는 고유한 Row Key가 있다. Row Key는 바이트 배열로 표시된다.
Row Key
Row Key를 기준으로 데이터가 모으기 때문에, Row 키는 적절하게 데이터가 분산될 수 있도록 디자인해야 한다. Row Key 디자인의 목표는 비슷한 Row가 서로 가까이 있는 방식으로 데이터를 저장하도록 하는 것이다.
- 임의의 Byte열로 사전순으로 내림차순 정렬.
- 빈 Byte문자열은 테이블의 시작과 끝을 의미.
- 문자열, 정수 바이너리, 직렬화된 데이터 구조까지 어떤 것도 로우키가 될 수 있음.
일반적으로 Row Key 패턴은 웹사이트 도메인 형식으로 구성할 수도 있다. org.apache.mair, org.apache.jira와 같이 도메인을 역순으로 저장하면 apache 도메인은 비슷한 위치에 데이터를 저장할 수 있다.
Column
Column Family와 Column Qualifier로 구성되어 있다.
Column Family
Column Family는 Row을 저장하는 데 사용되며, Apache HBase에 데이터를 저장하는 구조도 제공한다.
문자와 문자열로 구성되며 파일 시스템 경로와 함께 사용할 수 있다. 테이블의 각 행은 동일한 column family를 갖지만 모든 column family에 행을 저장할 필요는 없다.
Column Qualifier
Comumn Quailfier는 Column Family에 저장된 데이터에 대한 인덱스를 제공한다. Column quailfier는 고정된 값이 아니라서 다양한 데이터를 입력할 수 있다. 맵 객체라고 생각할 수 있다.
- Column들의 그룹으로 모든 컬럼패밀리의 Member는 같은 접두사를 사용.
- NOSQL:Cassandra와 NOSQL:HBASE 는 NOSQL이라는 컬럼 패밀리의 멤버컬럼.
- 컬럼패밀리 접두사는 반드시 표시할 수 있는 문자로 구성.
- 테이블 스키마에서 정의의 한 부분을 먼저 지정해야 함.
- 모든 컬럼패밀리 멤버는 물리적으로 파일시스템에서 함께 저장.
- 새로운 컬럼패밀리 멤버는 동적으로 추가 가능.
Cell
Cell은 Column family, Row key, Column qualifier의 구성된 데이터 단위이며, 각 컬럼의 값을 셀이라고 한다.
데이터 셀에는 value(값)과 timestamp(값의 버전)를 포함한다. timestamp가 있어서 이전의 값이 같이 저장되며, 일정 기간까지 그 값을 유지하도록 한다.
- ROW KEY & Column & Version이 명시된 튜플.
- 값은 임의의 Byte열이며 Timestamp.
- 테이블 셀은 버전 관리 됨(오직 셀들만).
Timestamp
Cell에 동일한 데이터가 저장된 값에는 버전이 지정되며, 각 버전은 생성 시간 동안 할당된 버전 번호로 식별된다. 데이터를 쓰는 동안 Timestamp를 언급하지 않으면 현재 시간이 지정된다.
HBase 데이터 유형(Data Types)
Apache HBase에는 데이터 유형 개념이 없다. 모두 바이트 배열이다. 값이 삽입되면 Put 및 Result 인터페이스를 사용하여 바이트 배열로 변환되는 일종의 byte-in 및 byte-out 데이터베이스이다. Apache HBase는 직렬화 프레임워크를 사용하여 사용자 데이터를 바이트 배열로 변환한다.
Apache HBase 셀에 최대 10~15MB의 값을 저장할 수 있다. 값이 더 큰 경우에는 Hadoop HDFS에 저장하고 파일 경로 메타데이터 정보를 Apache HBase에 저장할 수 있다.
HBase 데이터 저장소
다음은 Apache HBase의 물리적으로 저장되는 형태에 대해서 소개한다.
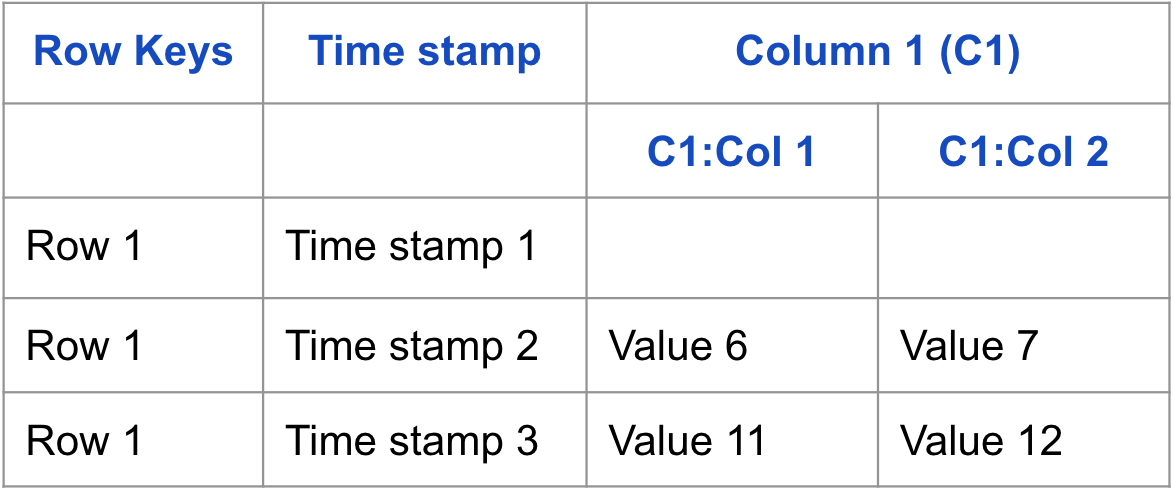
개념적 관점
테이블이 개념적 수준에서 일련의 Row으로 표시되는 것을 볼 수 있다.
다음은 데이터가 HBase에 저장되는 방식에 대한 개념도이다.
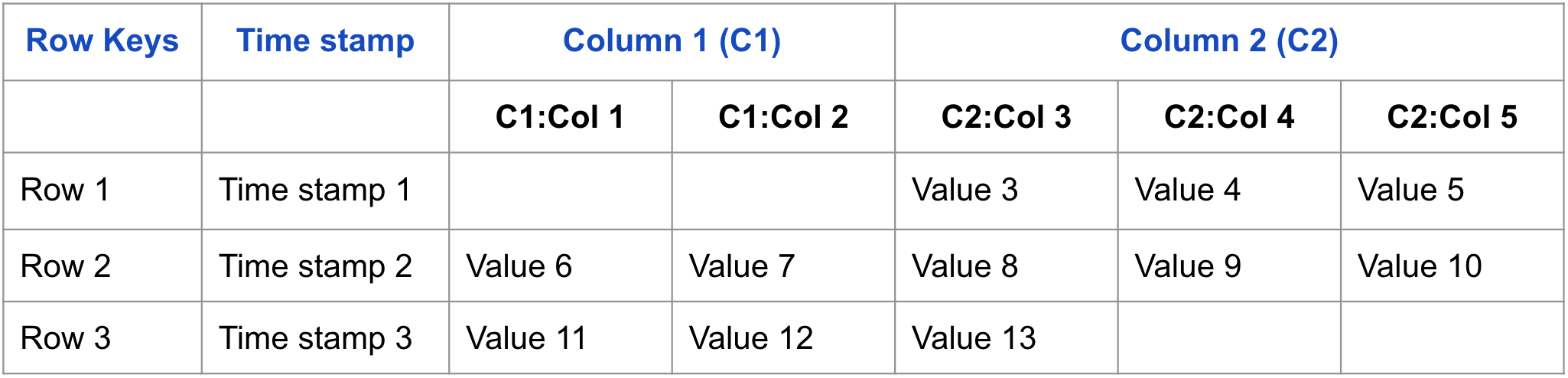
물리적 관점
Physical view 테이블은 column family에 의해 물리적으로 저장된다.
다음 예는 컬럼 계열 기반 테이블로 저장될 테이블을 나타낸다.
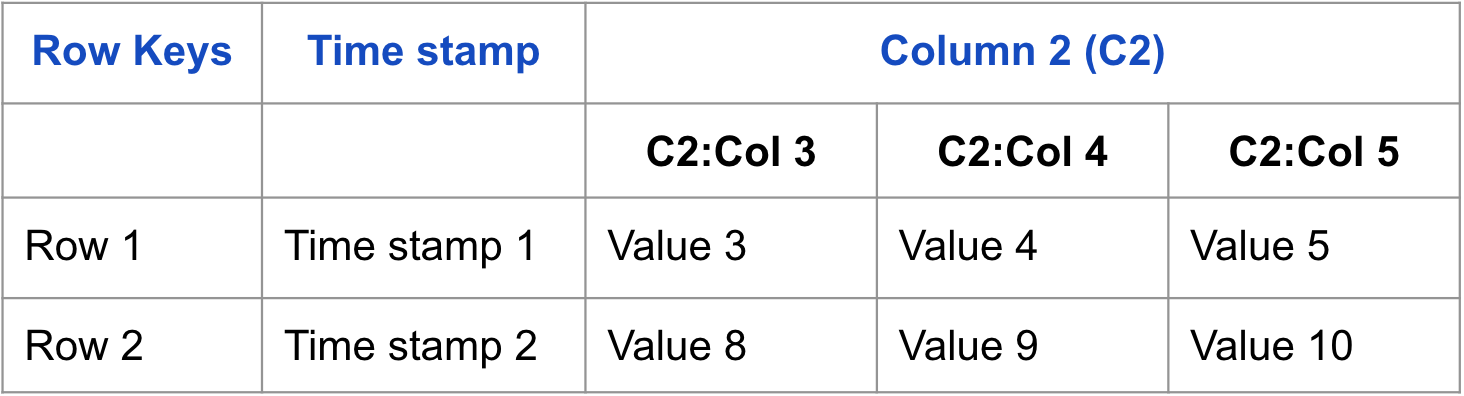
네임스페이스
네임스페이스는 테이블의 논리적 그룹이다. 그룹 관련 테이블의 관계형 데이터베이스와 유사하다.
네임스페이스의 표현을 살펴보겠다.
HBase Namespaces
- Table
- Region Server Group
- Permission
- Quota
네임스페이스 공간의 각 구성 요소를 살펴보겠다.
Table
모든 테이블은 네임스페이스의 일부입니다. 정의된 네임스페이스가 없으면 테이블이 기본 네임스페이스에 할당됩니다.
RegionServer group
네임스페이스에 대한 기본 RegionServer 그룹을 가질 수 있습니다. 이 경우 생성된 테이블은 RegionServer의 구성원이 됩니다.
Permission
네임스페이스를 사용하여 사용자는 읽기, 삭제 및 업데이트 권한과 같은 액세스 제어 목록을 정의할 수 있으며 쓰기 권한을 사용하여 사용자는 테이블을 생성할 수 있습니다.
Quota
이 구성 요소는 네임스페이스가 테이블 및 지역에 대해 포함할 수 있는 할당량을 정의하는 데 사용된다.
사전에 정의된 namespaces
미리 정의된 두 개의 특수 네임스페이스가 있다.
- hbase: HBase 내부 테이블을 포함하는 데 사용되는 시스템 네임스페이스이다
- default: 이 네임스페이스는 네임스페이스가 정의되지 않은 모든 테이블을 위한 것이다.
데이터 모델 작업
주요 작업 데이터 모델은 Get, Put, Scan 및 Delete이다. 이러한 작업을 사용하여 테이블에서 레코드를 읽고 쓰고 삭제할 수 있다.
각 작업을 자세히 살펴보겠다.
Get
Get 작업은 관계형 데이터베이스의 Select 문과 유사하다. HBase 테이블의 내용을 가져오는 데 사용된다.
아래와 같이 HBase 셸에서 Get 명령을 실행할 수 있다.
hbase(main) :001:0> get 'table name', 'row key' <filters>
Put
Put 작업은 테이블의 여러 행을 읽는 데 사용된다. 읽을 행 집합을 지정해야 하는 가져오기와 다릅니다. Scan을 사용하면 행 범위 또는 테이블의 모든 행을 반복할 수 있다.
Scan
스캔 작업은 테이블의 여러 행을 읽는 데 사용된다. 읽을 행 집합을 지정해야 하는 Get과 다르다. Scan을 사용하면 행 범위 또는 테이블의 모든 행을 반복할 수 있다.
Delete
삭제 작업은 HBase 테이블에서 행 또는 행 집합을 삭제하는 데 사용된다. HTable.delete()를 통해 실행할 수 있다.
삭제 명령이 실행되면 삭제 표시로 표시되고 압축이 발생하면 해당 행이 테이블에서 최종 삭제된다..
내부 삭제 종류는 아래와 같다.
- Delete : 특정 버전의 컬럼에 사용됩니다.
- Delete column : 모든 열 버전에 사용할 수 있습니다.
- Delete family : 특정 ColumnFamily의 모든 열에 사용됩니다.