HBase 압축 (컴팩션,Compaction) 및 데이터 블록 인코딩
압축 (컴팩션,Compaction)
HBase의 리전서버에 저장되어 있는 리전들은 Column Family 별로 HStore를 가지고 있는데, 이는 그 CF에 대한 MemStore와 HFile로 구성된다.
MemStore는 memory 영역에 있는 Column Family의 데이터이고 HFile은 로컬 디스크(HDFS)에 저장되어 있는 Column Family의 데이터로, 이렇게 계층화 하여 구성하는 이유는 HBase 테이블 구조에 맞추어 Row key 기반으로 정렬해야되기 때문에 디스크 영역으로 바로 저장할 수 없으며 메모리 영역에서 정렬 후 저장해야 한다.
HBase에서 쓰기작업(put, update 등)이 수행되는 경우 WAL(Write Ahead Log)에 데이터를 기록 후 MemStore에 데이터를 쓰게 되며, 읽기작업(scan)의 경우 MemStore를 우선적으로 확인 후 HFile을 탐색하여 요청한 내용을 확인하게 된다.
반복된 write 작업으로 MemStore의 데이터의 크기가 설정한 임계값을 초과하게 되는 경우 emStore의 데이터를 HFile로 저장한다. 이렇게 다수의 HFile로 구성된 리전의 경우 HFile이 많아지게 되면 compaction이 발생해 여러개의 HFile을 더 큰 것으로 병합하게 되며, 그 결과로 작은 크기의 여러개의 HFile이 큰 크기의 HFile로 개수가 줄어들게 된다. 이러한 작업을 컴팩션(compaction)이라고 한다.
HBase의 컴팩션 작업은 minor compaction과 major compaction으로 수행된다.
Minor Compaction
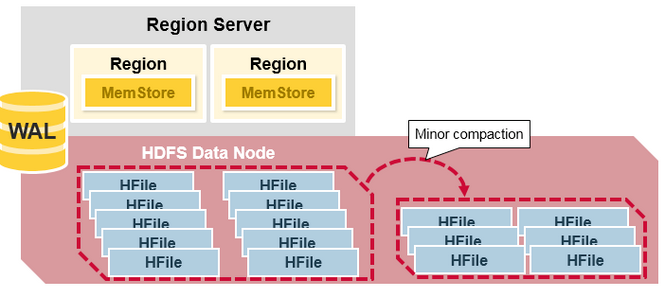
- Minor compaction은 최근에 생성된 크기가 작은 여러 개의 파일을 이보다 더 크게 설정된 크기의 HFile 크기로 병합하는 과정이다.
- 데이터를 입력하다 보면 여러 개의 작은 HFile들이 만들어진다. 파일들이 많아지면 성능이 떨어질 수 있는데, HBase는 자동으로 여러 개의 HFile들을 좀 더 큰 몇 개의 HFiles로 다시 만드는 식으로 HFile의 개수를 관리한다.
- HFile에 저장된 데이터는 정렬 되어 있으므로 merge sort를 이용해서 빠르게 합병할 수 있다.
Major Compaction
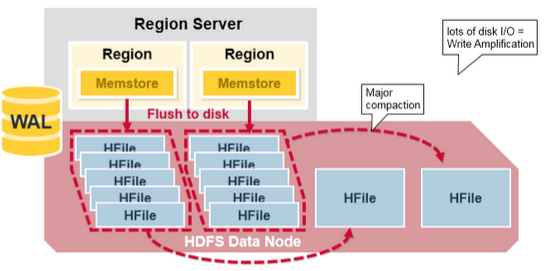
- Major compaction은 특정 리전 있는 Column Family의 모든 HFile들을 모아서 컬럼당 하나의 HFile로 만든다. 기본값 7일에 1번 수행한다.
- 이 과정에서 필요 없는 셀, 시간이 초과된 셀등을 제거해서 전반적인 읽기 성능을 높인다. Tombstones Marker가 존재하는 데이터를 최종적으로 이때 삭제한다.
- 작업이 이루어지면, 대량의 파일들에 대한 읽기/쓰기 작업이 일어나기 때문에 디스크 I/O와 네트워크 트래픽 증가가 발생할 수 있다.
- 그래서 자동으로 실행하도록 예약 할 수 있는데, 이를 이용해서 급작스러운 I/O의 증가가 서비스에 미치는 영향을 최소화하기 위해서 주말이나 야간으로 스케줄링하도록 할 수 있다.
압축 설정
Minor compaction은 아래와 같은 설정을 통해 컴팩션을 수행 할 HFile의 개수를 설정한다.
hbase.hstore.compaction.min- Minor compaction을 수행할 HFile의 최소 개수를 설정 한다.
- 기본 3인데, 2이상으로 설정해야 한다.
- 너무 큰 값을 넣을 경우 minor가 지연되어 나중에 한번에 처리하게 되면 부하가 걸리게 된다.
hbase.hstore.compaction.max- minor compaction을 수행할 HFile 최대 갯수를 설정
다음 설정을 통해서는 컴팩션을 수행할 HFile의 크기를 지정할 수 있다.
hbase.hstore.compaction.min.size: 이 값 보다 적은 HFile은 항상 minor compaction이 수행을 위한 탐색E xploringCompactionPolicy 시 포함된다. 이 값과 포함하여 hbase.hstore.compaction.ratio를 참조하여 컴팩션을 수행할 HFile을 선택하게 된다. 만약hbase.hstore.compaction.max.size: 이 크기보다 큰 HFile은 minor compaction에서 제외된다. 만약 minor compaction이 자주 발생하는데 큰 효과를 얻지 못하는 경우에는 이 값을 작게 설정하여 큰 파일들이 minor compaction에서 빠지도록 할 수 있다. (default :9223372036854775807, LONG.MAX_VALUE,byte
그 밖에 설정
hbase.hregion.majorcompaction- HBase는 하나의 Region에 대해서 여러 개의 StoreFile을 가질 수 있다. 그리고 주기적으로 성능 향상을 위해서 이 파일들을 모아서 하나의 더 큰 파일로 합치는 과정을 진행하게 된다. 그리고 이 과정은 많은 CPU usage와 Disk IO를 동반한다. 그리고 이때 반응 속도가 다소 떨어지게 된다. 따라서 반응 속도가 중요한 경우에는, 이 Major compaction을 off-peak 시간대를 정해서 manual 하게 진행하시는 것이 좋다.
- 기본값은 86,400,000 (ms)로 되어 있는데, 이 값을 0으로 바꾸시면 주기적인 Major Compaction이 돌지 않게 할 수 있다.
hbase.hregion.majorcompaction.jitter- 속성은 기본 0.2로 20%이다. 저장 파일별로 Major compaction이 수행되는 시점을 흩어지게 만든다.
- 만약 없으면 주 컴팩션이 매 24시간 마다 동시에 수행된다.
HBase 압축 및 데이터 블록 인코딩
이 섹션에서 언급된 코덱은 데이터 블록 또는 행 키를 인코딩 및 디코딩하기 위한 것이다. 복제 코덱에 대한 자세한 내용은 cluster.replication.preserving.tags를 참조하여라.
HBase는 ColumnFamily에서 활성화할 수 있는 여러 가지 압축(Compaction) 알고리즘을 지원한다. 데이터 블록 인코딩은 정렬된 행 키 및 주어진 테이블의 스키마와 같은 HBase의 기본 설계 및 패턴을 활용하여 키의 정보 중복을 제한하려고 시도한다. 압축기는 Cell에서 크고 불투명한 바이트 배열의 크기를 줄이고, 압축되지 않은 데이터를 저장하는 데 필요한 저장 공간을 크게 줄일 수 있다.
압축기와 데이터 블록 인코딩은 동일한 ColumnFamily에서 함께 사용할 수 있다.
변경 사항은 압축 시 적용된다.
ColumnFamily에 대한 압축 또는 인코딩을 변경하면, 압축 시에 변경 사항이 적용된다.
일부 코덱은 GZip 압축과 같이 Java에 내장된 기능을 활용한다. 다른 코덱은 네이티브 라이브러리에 의존한다. 네이티브 라이브러리는 HBase의 라이브러리 디렉터리에 설치된 코덱 종속성을 통해 사용할 수 있으며, Hadoop 코덱을 사용하는 경우 Hadoop의 일부로 사용할 수 있다. Hadoop 코덱에는 일반적으로 네이티브 코드 구성 요소가 있으므로 HBase에서 Hadoop 네이티브 라이브러리 활용하는데 Hadoop 네이티브 바이너리 지원 설치 지침을 따른다.
이 섹션에서는 HBase에서 사용 및 테스트되는 일반적인 코덱에 대해 설명한다.
어떤 코덱을 사용하든, 코덱이 올바르게 설치되어 있고 클러스터의 모든 노드에서 사용할 수 있는지 테스트해야 한다. 새로 배포된 노드에서 코덱을 사용할 수 있는지 확인하려면 추가 작업 단계가 필요할 수 있다. compression.test 유틸리티를 사용하여 지정된 코덱이 올바르게 설치되었는지 확인할 수 있다.
압축기를 사용하도록 HBase를 구성하려면 compressor.install을 참조하여라 ColumnFamily에 대해 압축기를 사용하도록 설정하려면 changing.compression을 참조한다. ColumnFamily에 대해 데이터 블록 인코딩을 사용하도록 설정하려면 data.block.encoding.enable을 참조한다.
Block Compressors
NONE
이 압축 유형 상수는 압축을 선택하지 않으며 기본값이다.
BROTLI
- Brotli는 범용 무손실 압축 알고리즘으로, LZ77 알고리즘의 최신 변형, 허프만 코딩, 2차 컨텍스트 모델링을 조합하여 데이터를 압축하며, 현재 사용 가능한 최고의 범용 압축 방법과 비슷한 압축률을 제공한다. GZ와 속도는 비슷하지만 더 밀도 높은 압축을 제공한다.
BZIP2
- Bzip2는 버로우즈 휠러 블록 정렬 텍스트 압축 알고리즘과 허프만 코딩을 사용하여 파일을 압축한다. 일반적으로 사전(LZ) 기반 압축기보다 압축률이 상당히 우수하지만 압축과 압축 해제 모두 다른 옵션에 비해 느릴 수 있다.
GZ(GZIP)
- 압축률을 중시
- gzip은 LZ77과 허프만 코딩의 조합인 DEFLATE 알고리즘을 기반으로 한다. 이 알고리즘은 Java 런타임 환경에서 보편적으로 사용할 수 있으므로 좋은 최하위 공통 분모 옵션이다. 그러나 Zstandard와 같은 최신 알고리즘과 비교하면 상당히 느리다.
LZ4
- 압축/해제 속도를 중시
- LZ4는 압축 및 압축 해제 속도에 중점을 둔 무손실 데이터 압축 알고리즘이다. Brotli, DEFLATE, Zstandard 등과 같은 LZ77 압축 알고리즘 제품군에 속한다. 마이크로 벤치마크에서 LZ4는 해당 제품군에서 압축과 압축 해제 모두에서 가장 빠른 옵션이며, 일반적으로 권장되는 옵션이다.
LZMA
- LZMA는 LZ77 알고리즘과 다소 유사한 사전 압축 방식으로, 계산 비용이 많이 드는 예측 모델과 가변 크기 압축 사전으로 매우 높은 압축률을 달성하는 동시에 일반적으로 사용되는 다른 압축 알고리즘과 비슷한 압축 해제 속도를 유지한다. LZMA는 일반적인 압축률에서는 다른 모든 옵션보다 우수하지만 압축기로서 특히 높은 수준의 압축에서 작동하도록 구성할 경우 매우 느릴 수 있다.
LZO
- 압축/해제 속도를 중시. 추가 라이브러리 설치 필요
- LZO는 압축 해제 속도에 중점을 두고 구현된 또 다른 LZ 변형 데이터 압축 알고리즘이다. LZ4만큼 빠르지는 않지만 거의 비슷한다.
SNAPPY
- 압축/해제 속도를 중시.
- SNAPPY는 LZ77의 아이디어를 기반으로 하지만 매우 빠른 압축 속도에 최적화되어 있으며, 거래(trade)에서 “합리적인(reasonable)” 수준의 압축만을 달성한다. LZ4만큼 빠르지만 압축률은 그다지 높지 않다. 저희는 모든 하드웨어 아키텍처의 모든 Java 런타임에 보편적으로 사용할 수 있는 옵션으로 GZ 대신 사용할 수 있는 순수 Java Snappy 코덱을 제공한다.
ZSTD
-
Zstandard는 유한 상태 엔트로피와 허프만 코딩을 모두 사용하는 대규모 검색 창과 빠른 엔트로피 코딩 단계가 있는 사전 매칭 단계(LZ77)를 결합한 것이다. 압축 속도는 가장 빠른 수준과 가장 느린 수준 간에 20배 이상 차이가 날 수 있지만, 압축 해제는 균일하게 빠르며 가장 빠른 수준과 가장 느린 수준 간에 20% 미만의 차이가 난다.
-
ZStandard는 사용 가능한 압축 코덱 옵션 중 가장 유연한 옵션으로, 레벨 1에서는 LZ4와 유사한 압축률(성능은 약간 떨어짐), 중간 레벨에서는 DEFLATE와 비슷한 압축률(성능은 더 우수함), 높은 레벨에서는 LZMA와 유사한 고밀도 압축(LZMA와 유사한 압축 속도)을 제공하는 동시에 보편적으로 빠른 압축 해제 속도를 제공한다.
Data Block Encoding Types
다섯 가지 데이터 블록 인코딩 유형이 HBase에서 제공된다. 구체적으로 다음과 같다.
- NONE
- Prefix
- Diff
- Fast Diff
- Prefix Tree
None
None은 아무런 인코딩이 적용되지 않는 것이며, 디폴트로 설정된다.
인코딩 적용되지 않은 ColumnFamily
다음 테이블은 데이터 블록 인코딩이 없는 가상의 ColumnFamily를 보여준다.
| Key Length | Value Length | Key | Value |
|---|---|---|---|
| 24 | … | RowKey:Family:Qualifier0 | … |
| 24 | … | RowKey:Family:Qualifier1 | … |
| 25 | … | RowKey:Family:QualifierN | … |
| 25 | … | RowKey2:Family:Qualifier1 | … |
| 25 | … | RowKey2:Family:Qualifier2 | … |
| … | … | … | … |
Prefix
일반적으로 키는 접두가가 같고, 마지막 부분만 다른 경우가 많다.
예를 들어, 첫번째 키는 RowKey:Family:Qualifier0이고, 다음 키는 RowKey:Family:Qualifier1일 수 있다. Prefix 인코딩에서는 현재 키와 이전 키 간에 공유되는 접두사의 길이를 보관하는 확장 컬럼이 추가된다. 여 예에서 첫 번째 키가 이전 키와 완전히 다르다면 접두사 길이는 0이고, 두 번째 키의 처음 23자가 동일하므로 접두사 길이는 23된다.
물론 두 키가 공통점이 전혀 없다면, Prefix는 별다른 이점을 제공되지 않는다.
Prefix 인코딩이 적용된 ColumnFamily
다음은 Prefix 데이터 인코딩이 적용된 동일한 데이터이다.
| Key Length | Value Length | Prefix Length | Key | Value |
|---|---|---|---|---|
| 24 | … | 0 | RowKey:Family:Qualifier0 | … |
| 1 | … | 23 | 1 | … |
| 1 | … | 23 | N | … |
| 19 | … | 6 | 2:Family:Qualifier1 | … |
| 1 | … | 24 | … | … |
| … | … | … | … | … |
Diff
Diff 인코딩은 Prefix 인코딩을 확장한 것이다. Key를 전체적으로 일련의 바이트로 순차적으로 취급하는 것이 아니라, Key의 각 부분을 보다 효율적으로 압축할 수 있도록 각 Key Field를 분할한다.
timestamp와 type이라는 두 개의 새로운 필드가 추가되었다.
ColumnFamily가 이전 행과 동일한 경우 현재 행에서 생략된다. Key 길이, value 길이, type이 이전 행과 동일한 경우 필드가 생략된다.
또한, 압축률을 높이기 위해 timestamp가 전체로 저장되지 않고, 이전 행의 timestamp와 차이(Diff)로 저장된다. 접두사 예제에서 두 개의 행 키가 있고 timestamp가 정확히 일치하고 type이 같다면, 두 번째 행에는 값 길이나 유형을 저장할 필요가 없으며, 두 번째 행의 timestamp 값은 전체 타임스탬프가 아닌 0이 된다.
쓰기 및 스캔 속도가 느려지지만, 더 많은 데이터가 캐시되므로 Diff 인코딩은 기본적으로 비활성화되어 있다.
Diff 인코딩이 적용된 ColumnFamily
이 테이블은 이전 테이블과 동일한 ColumnFamily에 Diff 인코딩이 적용된 것을 보여준다.
| Flags | Key Length | Value Length | Prefix Length | Key | Timestamp | Type Value | |||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 24 | 512 | 0 | RowKey:Family:Qualifier0 | 1340466835163 | 4 | … | ||
| 5 | - | 320 | 23 | 1 | 0 | - | … | ||
| 3 | - | - | 23 | N | 120 | 8 | … | ||
| 0 | 25 | 576 | 6 | 2:Family:Qualifier1 | 25 | 4 | … | ||
| 5 | - | 3384 | 24 | 2 | 1124 | - | … | ||
| … | … | … | … | … | … | … | … |
Fast Diff
Fast Diff는 Diff와 비슷하게 작동하지만 더 빠른 구현되었다. 또한 데이터 자체가 이전 행과 동일한지 여부를 추적하기 위해 단일 비트를 저장하는 필드를 하나 더 추가한다. 동일하면 데이터가 다시 저장되지 않는다.
키가 길거나 열이 많은 경우에 Fast Diff 코덱을 사용하는 것이 좋다.
데이터 형식은 Diff 인코딩과 거의 동일하므로 설명할 이미지가 없다.
Prefix Tree
Prefix Tree는 인코딩은 HBase 0.96에서 실험적 기능으로 도입되었다. Prefix Tree 인코딩은 Prefix, Diff 및 Fast Diff 인코더와 비슷한 메모리 절약 효과를 제공하지만 인코딩 속도가 느려지는 대신 더 빠른 랜덤 액세스를 제공한다. 이 기능은 좋은 아이디어였지만 거의 사용되지 않아 hbase 2.0.0에서 제거되었다.