HBase 블룸 필터 (BloomFilter)
BloomFilter이란?
BloomFilter는 1970년 Bloom이 제안한 다중 해시 함수 매핑을 위한 빠른 검색 알고리즘이다. 이 알고리즘은 일반적으로 요소가 집합에 속하는지 여부를 빠르게 판단해야 하는 상황에서 사용되는데, 엄격하게 100% 정확할 필요는 없다는 것에서 출발한다.
자세한 이론은 쉽게 설명하는 블룸필터(Bloom Filter) 데이터 스트럭처 페이지를 참고하여라.
HBase BloomFilter
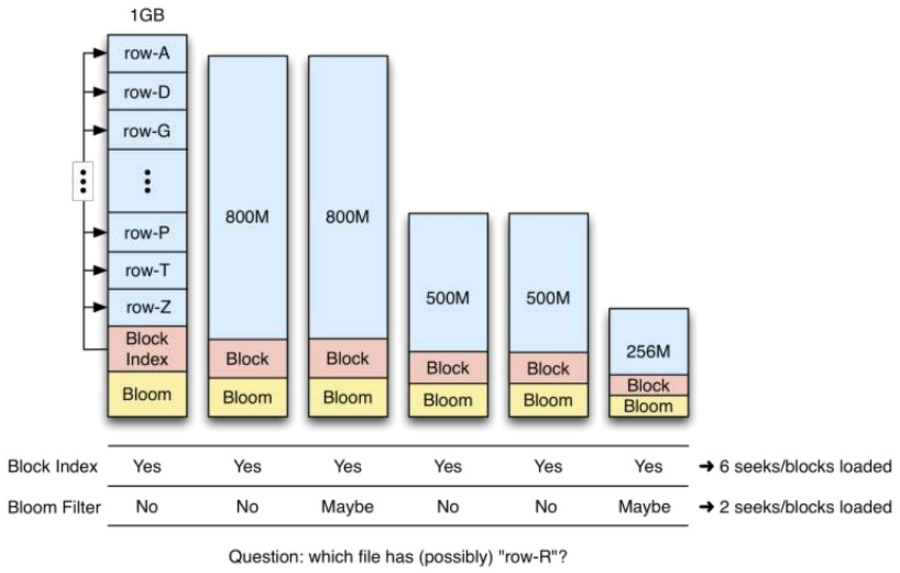
HBase의 BloomFilter의 데이터는 StoreFile의 메타에 저장되며, 한번 작성되면 StoreFile은 변경 불가능하므로 업데이트할 수 없다.
BloomFilter는 Column family 레벨의 구성 속성이다. 테이블에 BloomFilter가 설정되어 있으면 HBase는 MetaBlock이라고 하는 StoreFile을 생성할 때 BloomFilter 구조의 데이터 조각을 포함한다. MetaBlock 및 DataBlock(실제 KeyValue 데이터)은 LRU BlockCacheMaintenance에서 함께 사용된다.
따라서, BloomFilter를 설정하면, 특정 스토리지 및 메모리 캐시 오버헤드가 발생한다.
HBase BloomFilter 설정 방법
특정 Row key를 포함하고 있는지 탐색할 때, 기존 블록 색인에 비해 불필요한 블록 로딩을 줄여 클러스터의 전반적인 처리량이 개선된다.
셀 크기, 셀 개수, 데이터 저장 방식, 읽기 방식 등에 따라 블룸 필터를 선택해야 한다.
HBase 문서에 따르면 왠만한 경우에는 BloomFilter를 사용하는 것을 권장한다고 한다.
BloomFilter에는 NONE(기본값), ROW, ROWCOL의 3지 매개변수가 있다.
ROW: KeyValue의 행(Row)을 기준으로 StoreFile을 필터링하는 행 수준 Bloom 필터를 나타낸다.ROWCOL: KeyValue의 행(Row) + 열(Column)에 따라 StoreFile을 필터링하는 열 수준 Bloom 필터를 나타낸다.
따라서, ROWCOL의 공간 오버헤드가 ROW보다 높다.
해당 리전에 StoreFile가 많을수록 BloomFilter의 효과가 더 좋고, 리전의 StoreFile 수가 적을수록 HBase 읽기 성능이 향상된다.
다음과 같이 BloomFilter 명령을 활성화하도록 HBase에서 Column family열 패밀리를 설정한다.
create 't1',{name => 'c1', BLOOMFILTER => '<ROW 또는 ROWCOL>'}