그래프 데이터베이스 퀵 스타드 가이드
그래프 데이터베이스란?
그래프 데이터베이스는 말그대로 그래프를 처리하는 데이터베이스이다. 많이 사용되는 관계형 데이터베이스는 테이블 구조를 다루는 데이터베이스라고 할 수 있다.
관계형 데이터베이스는 여러 테이블 구조의 관계를 처리할 수 있지만 실제로 관계를 다루는 것은 어려운 경우가 많다. 관계를 나타 내기 위해 적절한 스키마 디자인이 필요하며 쿼리는 어렵다. 또한 테이블을 조인하는데 비용이 많이 든다.
그래프 데이터베이스는 화이트보드에 다이어그램을 그리듯이 데이터를 처리할 수 있는 장점이 있다. 연결된 데이터를 직관적으로 조작할 수 있다. 반대로 연결되지 않은 데이터를 다루는데는 적합하지 않다.
그래프 데이터 모델
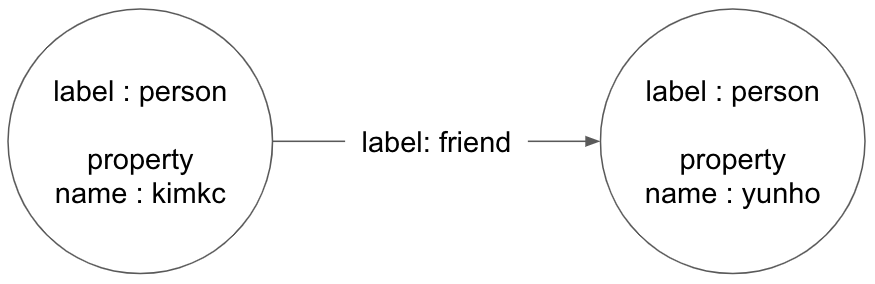
일반적으로 자주 사용되고 있는 것은 프로퍼티 그래프로 프로퍼티 그래프는 아래와 같은 특징이 있다.
- 그래프에는 노드(node, 정점, 꼭지점)와 엣지(edge, 간선, 변)가 있다.
- 노드에는 레이블과 속성(키-값 쌍)이 있다.
- 엣지에는 레이블과 방향이 있으며 시작 노드와 끝 노드가 있다.
- 엣지에는 물론 속성을 포함할 수 있다.
실제로 그래프 데이터베이스를 사용해 보자.
그래프 데이터베이스를 이해하려면 실제로 사용해 보는 것이 빠르다. Docker를 사용하려면 사전에 Docker 설치가 필요하다.
그래프 데이터베이스 사용을 위한 준비
샘플 데이터를 클론한다.
실제로 그래프에서 데이터를 사용해 보면 알기 쉽기 때문에 샘플 데이터를 먼저 클론한다.
아래 저장고는 PRACTICAL GREMLIN: An Apache TinkerPop Tutorial에서 사용되는 항공로에 대한 데이터이다.
% git clone https://github.com/krlawrence/graph.git
그래프 스토어를 시작하고 샘플 데이터 로드
Docker에서 그래프 데이터베이스를 시작하고 샘플 데이터를 로드한다.
Docker 이미지는 tinkerpop/gremlin-console을 사용한다.
Gremlin Console에는 TinkerGraph라는 온-메모리 그래프 스토어가 함께 제공된다.
% cd graph/sample-data
% docker run -it --rm -v `pwd`:/mydata tinkerpop/gremlin-console
gremlin> :load /mydata/load-air-routes-graph-34.groovy
그래프 탐색
Gremlin
관계형 데이터베이스에서 사용되는 SQL과 마찬가지로 그래프 데이터베이스에 대한 몇 가지 쿼리 언어가 있다.
여기에서는 Gremlin을 사용한다. Gremlin에서는 메소드 체인과 같은 설명으로 그래프를 추적한다.
그래프 추적
Gremlin에서 쿼리는 기본적으로 g부터 시작된다. 이는 그래프에 액세스하기 위한 traversal 객체라고 불리는 것이다.
이 traversal 객체는 스스로 좋아하는 변수에 할당할 수 있지만, g라는 변수에 바인딩하는 경우가 많다. 샘플 데이터를 로드한 시점에, 이미 g에 바인딩되어 있다.
첫번째 쿼리
노드 조회
샘플 데이터의 항공로 데이터를 추적해 보자. 우선, 그래프의 모든 노드(정점)를 취득해 보겠다.
gremlin> g.V()
==>v[0]
==>v[1]
==>v[2]
==>v[3]
==>v[4]
==>v[5]
==>v[6]
==>v[7]
==>v[8]
==>v[9]
... 생략 ...
==>v[996]
==>v[997]
==>v[998]
==>v[999]
...
당연히 많은 양의 노드가 반환된다.
총 몇건이 있는지 조회해 보자.
gremlin> g.V().count()
==>3619
노드는 라벨로 필터링 하지 않으면, 공항 이외의 노드도 조회되므로 공항(airport)의 노드만의 건수를 세어 보겠다.
hasLabel로 레이블을 조회 할 수 있다.
gremlin> g.V().hasLabel('airport').count()
==>3374
인천 공항 코드(ICN)를 가진 공항을 찾아 보겠다. has로 속성의 키와 값을 전달하여 조회 할 수 있다.
gremlin> g.V().hasLabel('airport').has('code','ICN')
==>v[122]
단, 하나의 노드를 얻을 수 있었다! 인천 공항의 노드가 어떤 속성을 가지고 있는지 살펴 보겠다.
gremlin> g.V().hasLabel('airport').has('code','ICN').valueMap()
==>[country:[KR],code:[ICN],longest:[13000],city:[Seoul],elev:[23],icao:[RKSI],lon:[126.450996398926],type:[airport],region:[KR-28],runways:[3],lat:[37.4691009521484],desc:[Seoul, Incheon International Airport]]
노드 따라가기
out를 이용하여, 나가는 방향의 정점이나 엣지를 찾을 수 있다.
공항과 공항은 route라는 라벨의 엣지로 연결되어 있으므로 인천 공항에서 나가는 루트의 수를 세어 보겠다.
gremlin> g.V().hasLabel('airport').has('code','ICN').out('route').count()
==>144
144개의 경로가 있음을 알 수 있다.
실제로 어떤 공항으로 가는지 보자. 속성 값을 가져오려면 values을 사용한다. 키 이름을 전달하여 특정 속성의 값을 얻을 수 있다.
gremlin> g.V().hasLabel('airport').has('code','ICN').out('route').values('code')
==>BKK
==>SVO
==>HND
==>DOH
==>MXP
==>NBO
==>MEX
==>WAW
...
인천 공항에서 환승을 한 번 사용하는 것을 허용하면, 얼마나 많은 공항에 갈 수 있을까?
gremlin> g.V().hasLabel('airport').has('code','ICN').out('route').out('route').count()
==>11386
등록된 공항 수보다 많은 수가 반환 되었다. 이는 중복이 제거되지 않았기 때문이다. 중복을 제거하려면 dedup을 사용한다.
gremlin> g.V().hasLabel('airport').has('code','ICN').out('route').out('route').dedup().count()
==>1817
그리고, 환승을 1회 사용하지만, 직행으로 갈 수 있는 루트를 제거해 보자. aggregate으로 일시적으로 컬렉션을 저장하고, where로 제거한다.
gremlin> g.V().hasLabel('airport').has('code','ICN').out('route').aggregate('nonstop').out('route').where(without('nonstop')).dedup().count()
==>1673
인천 공항(ICN)에서 나와 김포 공항(GMP)으로 돌아오는 루트는 어떤 루트가 있습니까?
gremlin> g.V().hasLabel('airport').has('code','ICN').out('route').out('route').has('code', 'GMP').path().by('code')
==>[ICN,HND,GMP]
==>[ICN,KIX,GMP]
==>[ICN,NGO,GMP]
==>[ICN,CJU,GMP]
==>[ICN,PEK,GMP]
하네다 공항(HND) 등을 경유하는 루트가 목록으로 반환되었다.
조금 더 노드 따라가기
한국과 일본을 잇는 공항의 루트를 받아 온다.
gremlin> g.V().hasLabel('airport').has('country','KR').out('route').has('country','JP').path().by('code')
==>[ICN,HND]
==>[ICN,FUK]
==>[ICN,KIX]
==>[ICN,CTS]
==>[ICN,NGO]
==>[ICN,HIJ]
==>[ICN,KOJ]
==>[ICN,OIT]
==>[ICN,KMQ]
==>[ICN,YGJ]
==>[ICN,MYJ]
==>[ICN,TAK]
==>[ICN,KIJ]
==>[ICN,SDJ]
==>[ICN,OKA]
==>[ICN,UBJ]
==>[ICN,KMI]
==>[ICN,KKJ]
==>[ICN,HSG]
==>[ICN,KMJ]
==>[ICN,NGS]
==>[ICN,TOY]
==>[ICN,OKJ]
==>[ICN,AOJ]
==>[ICN,AXT]
==>[ICN,FSZ]
==>[ICN,NRT]
==>[CJU,NRT]
==>[CJU,FUK]
==>[CJU,KIX]
==>[CJU,NGO]
==>[PUS,NRT]
==>[PUS,FUK]
==>[PUS,KIX]
==>[PUS,CTS]
==>[PUS,NGO]
==>[PUS,OKA]
==>[GMP,HND]
==>[GMP,KIX]
==>[GMP,NGO]
==>[TAE,NRT]
==>[TAE,FUK]
==>[TAE,KIX]
==>[TAE,CTS]
==>[TAE,OKA]
대부분 인천발이다. 이해하기 쉽게 계산해 보자.
어디에서 그룹화할지 알 수 있도록 중간에 as 이름을 붙여 참조해야 한다.
gremlin> g.V().hasLabel('airport').has('country','KR').as('kr').out('route').has('country','JP').select('kr').groupCount().by('code')
==>[ICN:27,TAE:5,GMP:3,CJU:4,PUS:6]
일본으로 가는 루트는 인천 공항발이 27개, 부산 공항발이 6개가 있는 것을 알았다.
한국과 일본의 최장 경로는 어디일까? 각 엣지에는 거리가 있기 때문에 이를 참조하여 조회해 보자.
엣지에 봐야 하기에 out이 아닌 outE와 inV를 사용하여, order로 정렬해 보겠다.
gremlin> g.V().hasLabel('airport').has('country','KR').outE('route').order().by('dist',desc).inV().has('country','JP').path().by('code').by('dist')
==>[ICN,882,CTS]
==>[PUS,861,CTS]
==>[TAE,841,CTS]
==>[CJU,804,NRT]
==>[ICN,795,AOJ]
==>[ICN,790,SDJ]
...
인천 공항(ICN)과 신치토세 공항(CTS)을 연결하는 882마일이 가장 긴 것을 알 수 있다.
그래프 데이터베이스의 특징, 어려운 점
실제로 그래프 데이터베이스를 사용해 보면 연결이 있는 데이터를 쉽게 끌어 당길 수 있다는 것을 알 수 있다.
그러나, 그래프 데이터베이스라고 해도 무엇이든 끌어 당길 수 있는 것은 아니다. 그래프 데이터베이스에서 참조하는 노드와 에지 수가 증가하면 응답이 느려진다.
예를 들어, 수백만 팔로워가 있는 유명인이 존재하는 소셜 그래프의 경우, 그 유명인을 팔로우하고 있다는 조건으로 시작하여 순회해 나가면, 수백만 엣지를 참조하게 되므로 즉시 결과를 돌려주는 것 어려워진다.
효율적인 쿼리를 작성하는 것은 물론 중요하지만, 시스템으로 사용할 계획인 일반적인 쿼리를 효율적으로 처리할 수 있도록 그래프를 배치해야 한다. 또, 그래프에 모든 데이터를 보존할 필요는 없고, 다른 데이타베이스 시스템과 조합해 알맞게 곳에 배치하여 이용하는 것이 중요하다.
데이터로서 관계성을 다루고 있지만, MySQL에서 JOIN하는 것이 힘들었다면, 꼭 한번 그래프 데이터베이스를 이용해 보길 바란다.
참고문헌
- PRACTICAL GREMLIN: An Apache TinkerPop Tutorial
- 좀 더 Gremlin에서 여러가지 시험해보고 싶은 분에게 추천하는 Tutorial이다.
- O’Reilly - Graph Databases
- 이용하고 있는 쿼리 언어는 다르지만, 그래프 데이터베이스에 대해서 설명한다.
- TinkerPop Documentation
- 포괄적인 문서이다.