쉽게 설명하는 블룸필터(Bloom Filter) 데이터 스트럭처
블룸필터(Bloom Filter)?
블룸필터(Bloom Filter)는 효율이 좋은 확률적인 데이터 스트럭처이다. 요소가 집합의 요소인지 여부를 테스트하는 데 사용된다. 블룸필터는 바이너리트리나 해쉬맵처럼 자주 사용되는 데이터 스트럭처는 아니지만, 간혹 사용되곤 한다.
기본적인 개념은 굉장히 간단하고, 다음과 같은 상황에 굉장이 유용하다.
어떤 Set(즉, 집합)과 Element가 있을 때, 특정 Element가 그 Set에 존재 여부를 블룸필터를 사용하면 빠르게 알 수 있다. 특정 Element가 특정 Set에 존재하냐고 하였을 때, 블룸필터는 두가지 답을 할수 있다.
- 특정 Element가 특정 Set 안에 존재하지 않는다.
- 특정 Element는 특정 Set 안에 존재 할 수 도 있다.
이 두가지 답은 Element가 필터에 존재하지 않을 때는 확실히 알려줄 수 있지만, 존재를 할 때는 확실하지 않다는 것을 뜻한다.
정확하지 않은데도 사용하는 이유는 Bloom Filter는 공간 효율적인 데이터 구조이다. 이는 사용하는 메모리 영역을 처음부터 고정해도 좋다. Bloom Filter의 요소 단위는 비트이다. 32bit 머신으로 integer형이라면 최대 32개의 요소가 넣는다.
블룸필터 구성
그럼, 블룸 필터가 동작에 대해서 설명하도록 하겠다. 블룸필터는 블품 1개의 배열과 n개의 Hash 함수로 구성된다.
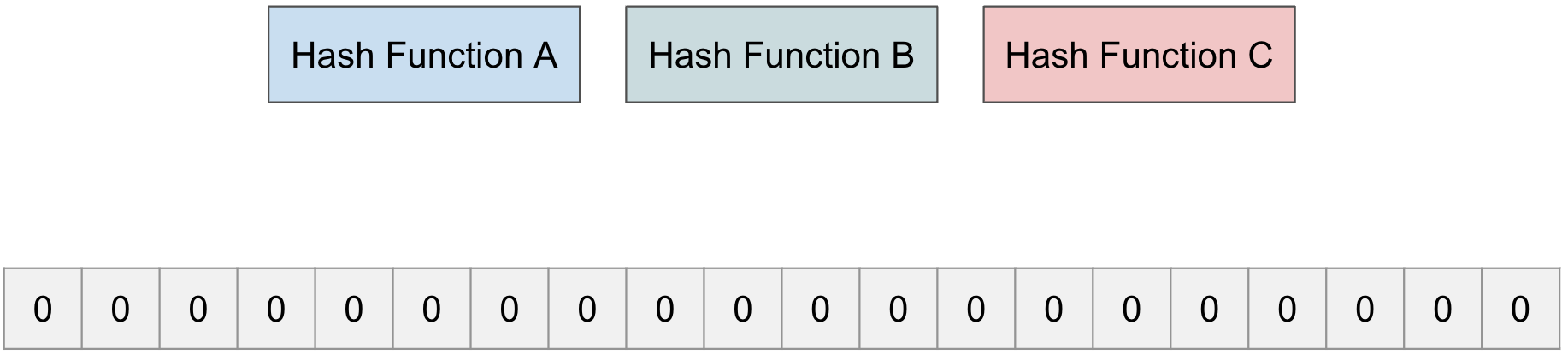
n개의 Hash 함수
Bloom Filter는 여러 Hash 함수를 사용한다.
Hash 함수는 어떤 값을 전달하였을 때, 그 값은 배열의 인덱스 중에 하나의 숫자로 바꿔 주는 역할을 한다.
Hash 함수의 개수는 여러개로 정할 수 있고, 각 함수는 Hash를 하는 방식이 각자 다르다.
이 함수의 기능은 아래와 같다.
- Set에 새로운 Element를 추가한다.
- Set에 입력한 Element가 존재하는지 확인한다.
여러 값을 갖는 배열
블룸 필터는 여러 값을 같는 배열로 이뤄져 있고, 어떤 값을 Hash 함수를 통해서 나온 인덱스 중에 하나를 숫자를 바꿔주게 된다.
예제의 배열의 크기는 20의 Bloom Filter를 예로 한다.
블룸필터에 새로운 Element 추가
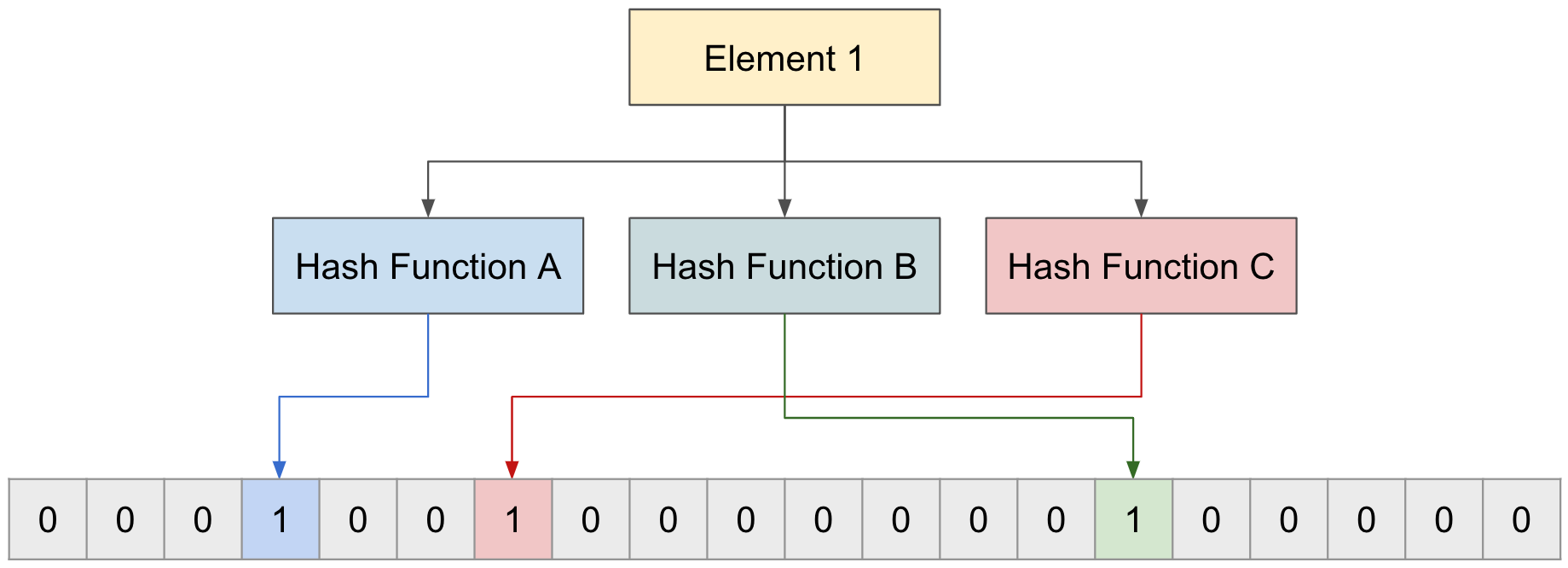
블룸 필터에 “Element 1"를 각 3개의 함수를 통해서 인덱스를 받아오고 해당 인덱스에 값을 0에서 1로 변경한다.
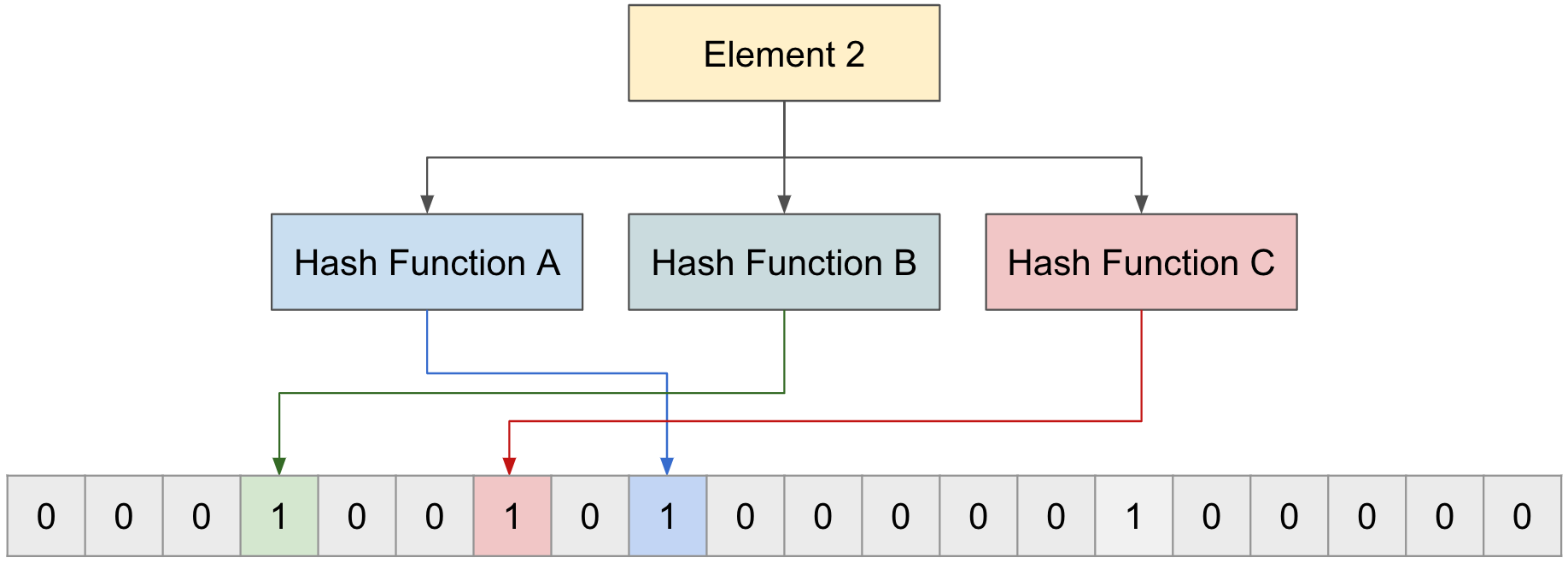
두번째 “Element 2"도 동일하게 각 3개의 함수를 통해서 인덱스를 받아오고 해당 인덱스에 값을 0에서 1로 변경한다.
블룸필터에 새로운 Element 확인
“Element 3"가 존재하는지 알아보기 위해 함수 3개 통과해 본다.
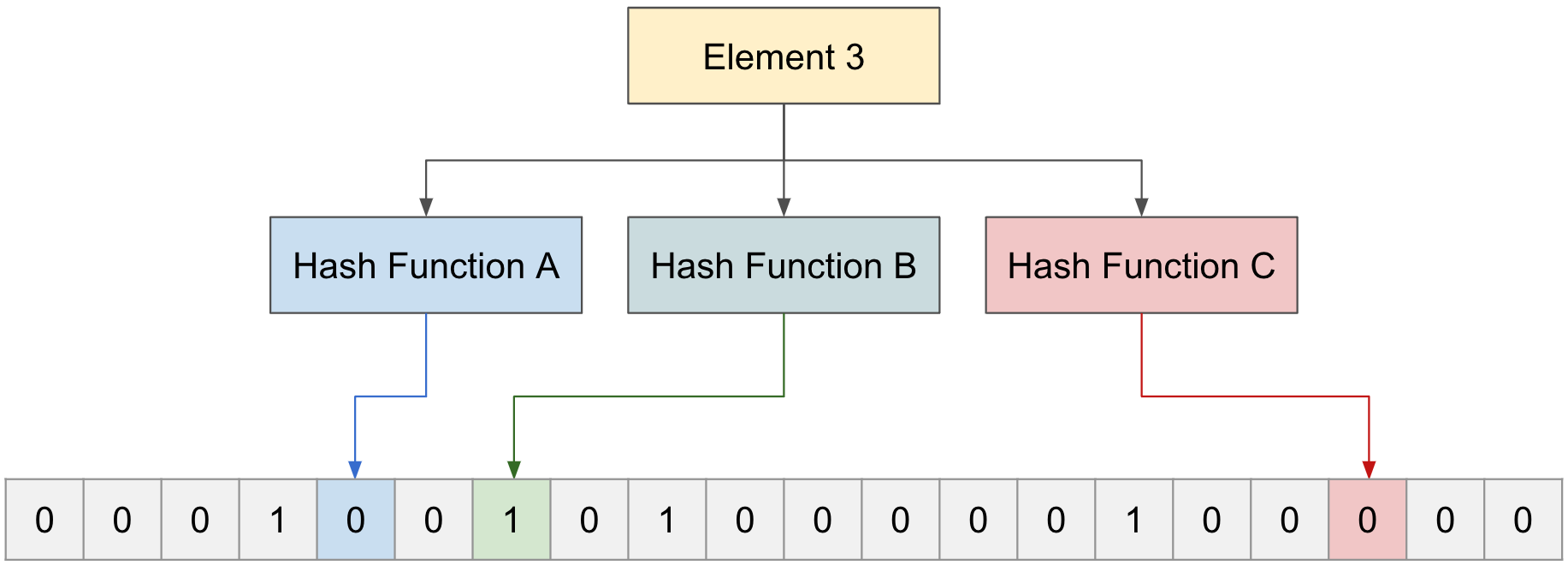
Hash 함수 A,B,C 에서 각각 0,1,0을 가르키게 되고, 1개라도 0을 포함하게 되면, 입력 받은 “Element 3"은 존재하지 않는다.
이번에는 “Element 4"가 존재하는지 알아보기 위해 함수 3개 통과해 본다.
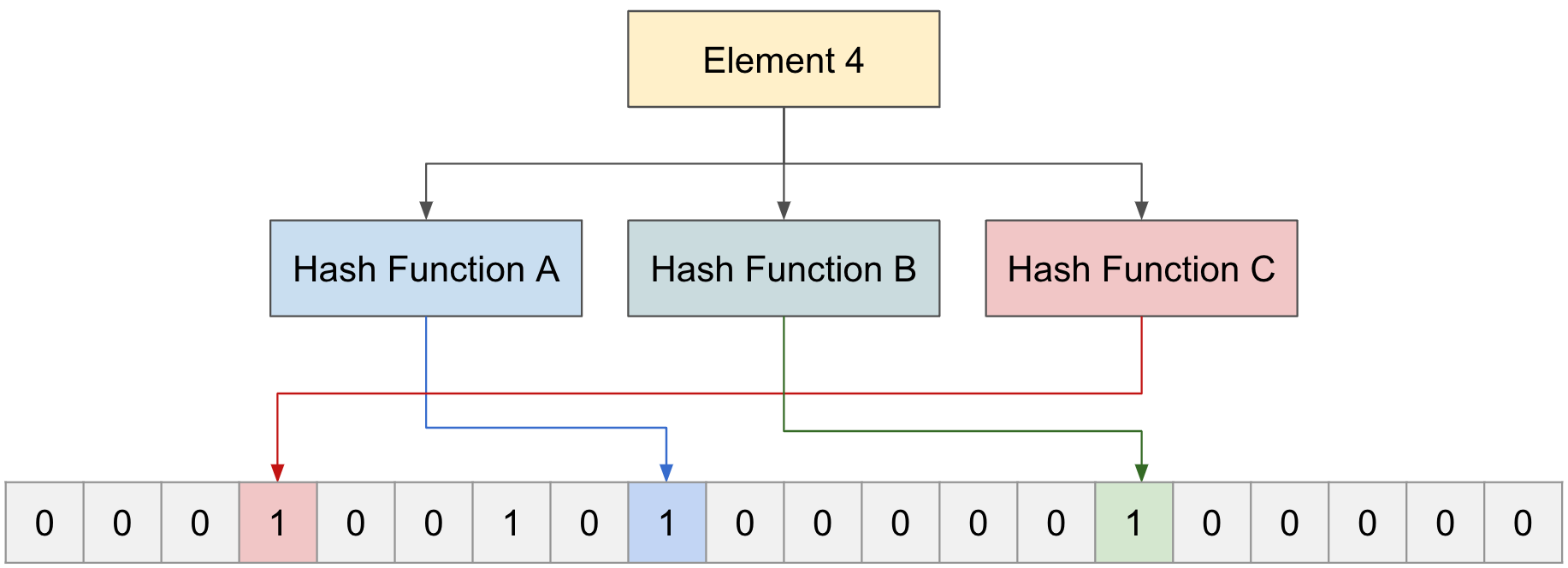
함수 A,B,C가 모두 1을 값을 가르키고 있지만, 실제로는 “Element 1,2"만 존재하지, “Element 4"는 존재하지 않았다.
이렇게 존재하지 않는 “Element"는 확실히 존재하지 않다는 것을 알려줄수 있지만, 확실히 존재하지 않았던 “Element"에 대해서는 확률적으로나 알려줄수 있지 정확하게 않다.
블룸필터를 사용하는 예제
그럼 이렇게 확실하지 않은데 사용하는 이유는 무엇인가? 그 이유는 블룸 필터가 굉장히 메모리 효율적(Efficient)이고, 빠르기 때문이다.
다음 블룸필터를 사용하는 2가지 경우를 살펴 보도록 하겠다.
CDN
CDN은 많은 사용자가 요청하는 데이터를 사용자들에 가까이 있는 CDN에 저장을 해서 다운로드 받기 쉽게 하기 위한 것이다.
CDN에서는 요청에 대한 Caching을 하게 될 건데, 첫번째 요청이 있었을 때 바로 캐싱이 된다고 생각해 하자. 그렇게 되면 여러번 요청이 안되고, 한번만 요청이 되는 경우에도 다 캐싱을 하게 될것이다. 이는 효율성은 떨어지게 된다.
CDN 사업하는 Akamai라는 회사에 따르면, 4분의 3정도가 한번 밖에 요청이 되지 않는 데이터라고 한다. 그래서 생각해낸 방안이, 첫번째 요청이 왔을 때는 블룸 필터에만 표시해 놓고, 리소스를 cdn에 캐시 안하고 사용자에 전달한다. 해당 리소스가 다시 요청이 들어왔을 때 블룸필터를 확인하여 전에 요청이 되었던건지 여부를 확인할 수 있게 된다. 그러므로써 해당 리소스가 여러번 요청이 되는 것을 알게 되고, 그때 부터 캐싱을 하게 했다고 한다.
Key Value Store
Key value Store 에서 Key 를 fetch 할 때, Row이 존재하는 여부를 확인하게 되게 된다. 이때, Key가 없는 경우에 모든 Row를 확인해야 하므로 최악의 경우로 가장 느려지는데, 왜냐하면 있는 Key는 인덱스 같은 곳을 확인하였을 때, 경우에 따라 확인하자마자 그 Key 바로 찾을 있을 수도 있고, 인덱스를 몇번을 보다가 찾을 수 있다. 그러나, 그 Key 없다면 최악의 경우로 존재하는 모든 인덱스, 데이터 셋을 다 조회해야 없다는 것을 확실 할 수 있게 된다.
이때, 최악의 경우는 없는 Key 를 요청시에 대비하여 블룸 필터를 사용할 수 있다. Bloom Filter 를 사용하면 빠르게 (약간의 에러가 있을 수 있지만) Key 존재하지 않는지 Key가 존재하는지 확인 할 수 있다.
아래와 같은 데이터 저장소가 Bloom Filter 를 사용하고 있다고 한다.
- Google Bigtable
- HBase
- Redis
- Cassandra
- PostgreSQL